
Part 3 explores three advanced capabilities that transformed query processing and context generation in the GraphRAG system. First, we introduced configurable semantic relationship selection to allow intelligent filtering mechanism that prioritizes relationship types based on their semantic relevance to your content corpus. Next, we prtalk about intelligent query routing system that analyzes user queries to classify them into 5 distinct types and automatically selects from 6 specialized retrieval strategies for optimal context generation. Finally, wblog covers flexible context formatting with 5 output formats designed for different consumption patterns, such as conversational AI interfaces or articles generation. These capabilities enable the GraphRAG system to deliver precise, context-aware responses across diverse query patterns and use cases.
Introduction
In Part 2 of this series, we explored how cross-document relationship aggregation and multi-hop graph traversal enable discovery of entity connections across documents. We also talked about entity-centric knowledge subgraphs with AI-powered summarization for local context retrieval with citations, and a sophisticated multi-space retrieval foundation supporting entity, relationship, summary, and chunk vectors.
Building upon that foundation, Part 3 introduces three new capabilities that transform our GraphRAG system from a multi-vector retrieval engine into an intelligent, adaptive query processing pipeline:
- Configurable Semantic Relationship Selection provides control over which relationship types enter the vector space through intelligent semantic relevance scoring. Rather than embedding any relationship types indiscriminately, the system allows you to configure which relationships carry semantic value for your documents.
- Intelligent Query Routing System eliminates the need for manual strategy selection by automatically classifying queries into 5 distinct types and routing them to optimal retrieval strategies. The system employs a multi-level classification approach, including Claude AI semantic analysis to determine whether a query requires entity-centric search or relationship graph traversal.
- Context Formatting Pipeline addresses a challenge of context presentation by supporting 5 specialized output formats. Whether generating context for conversational AI or for an application integration the formatting layer ensures retrieved context matches consumption requirements.
These capabilities work together to allow our GraphRAG system to adapt its retrieval strategy and output format to match query intent, content type, and consumption context. Thus, delivering both precision and flexibility across diverse use cases.
Configurable Semantic Relationship Selection
One of the key enhancements in the Multi-Vector Retrieval (MVR) system is the introduction of intelligent relationship filtering. This feature gives you a fine-grained control over which relationship types are embedded in the vector database, enabling optimization for both semantic relevance and system performance.
Semantic Value Prioritization
The MVR system now distinguishes between high-value semantic relationships and low-value statistical relationships. Rather than embedding every relationship in the knowledge graph, the system allows you to specify which relationship types carry genuine semantic meaning worthy of vector representation.
By default, the system embeds 14 high-value relationship types:
AI-Extracted Semantic Relationships:
- Business relationships: FOUNDED, ACQUIRED, PARTNERED_WITH, COMPETED_WITH
- Professional relationships: WORKS_FOR, COLLABORATED_WITH, LEADS
- Creation relationships: CREATED, INVENTED, PUBLISHED
- – Financial relationships: `FUNDED_BY`, `AFFILIATED_WITH`
Author Relationships:
- Document authorship: AUTHORED_BY
- Institutional affiliations at the time document was created: WORKED_AT
These relationships are extracted through AI-powered entity recognition, carry rich contextual information, and typically have high confidence scores (0.7-0.95). Each embedded relationship includes metadata like project names, dates, roles, and cross-document consensus scores.
What Gets Excluded
Statistical co-occurrence relationships like MENTIONED_WITH are by default excluded from vector embedding. While these relationships remain valuable for graph traversal and are preserved in Neo4j, they don’t need vector representation since:
1. Entity embeddings already capture co-occurrence semantics – entities appearing together in documents naturally have similar embeddings
2. Chunk embeddings provide contextual coverage – original text chunks preserve all co-occurrence information
3. Dedicated co-occurrence search – the new /search/entity-cooccurrences API endpoint provides fast graph-based co-occurrence discovery without requiring embeddings.
Configuration-Driven Design
The filtering system is fully configurable through environment variables:
# Core filtering
MVR_SEMANTIC_RELATIONSHIPS_ONLY=true
MVR_INCLUDE_MENTIONED_WITH=false
# Custom relationship types
MVR_HIGH_VALUE_RELATIONSHIPS=["FOUNDED","CREATED","WORKS_FOR",...]
# Quality thresholds
MVR_RELATION_MIN_CONFIDENCE=0.6
MVR_MENTIONED_WITH_MIN_OCCURRENCES=5
This allows us to:
- Customize for domain requirements – add domain-specific semantic relationships
- Adjust quality thresholds – filter by confidence levels or occurrence counts
- Balance coverage vs. performance – include more types for comprehensive search or fewer for optimized performance
- Enable/disable filtering – toggle semantic filtering on/off per deployment
Technical Implementation
The filtering logic is implemented at the service layer:
# app/services/relation_embedding_service.py
async def get_relationships_for_embedding(
self,
relationship_types: Optional[List[str]] = None) -> List[RelationData]:
"""
Retrieve only semantically valuable relationships for embedding.
"""
if relationship_types is None:
relationship_types = HIGH_VALUE_RELATIONSHIP_TYPES
query = """
MATCH (source)-[r]->(target)
WHERE type(r) IN $relationship_types
AND r.confidence >= $min_confidence
RETURN ...
"""
# Filters at Neo4j level for efficiency
The system validates requested relationship types and provides warnings when excluded types are requested:
# Validation with helpful feedback
validation = await service.validate_relationship_types(["FOUNDED", "MENTIONED_WITH"])
# Returns: {
# "valid_types": ["FOUNDED"],
# "invalid_types": ["MENTIONED_WITH"],
# "warnings": ["MENTIONED_WITH excluded from MVR ..."]
# }
Search API Impact
The relation search endpoint now focuses exclusively on semantic relationships:
# Semantic relationship search
POST /api/documents/search/relations
{
"query": "who founded OpenAI",
"relationship_types": ["FOUNDED", "CREATED"],
"min_confidence": 0.7
}
# Returns high-value semantic facts with rich context
For co-occurrence discovery, a dedicated API endpoint leverages the Neo4j graph:
# Entity co-occurrence search
GET /api/documents/search/entity-cooccurrences/OpenAI?top_k=20
# Returns entities that co-occur with OpenAI, enriched with entity embedding metadata
# Uses Neo4j MENTIONED_WITH relationships + ChromaDB entity embeddings
System Performance Improvements
Optimized MVR design delivered significant performance improvements:
- Vector collection size: ~95% reduction in relation embeddings
- Embedding generation: ~20x faster (hours → minutes for large corpora)
- Search performance: <200ms for semantic relationship queries
- Scalability: Linear scaling to 100,000+ documents
Use Cases
Apart from system performance optimization, introduction of intelligent relationship filtering allowed us to support several powerful patterns by prioritizing specific entity relationships:
1. Domain-Specific Semantic Graphs
# Legal document repository
MVR_HIGH_VALUE_RELATIONSHIPS=[
"CITES", "OVERRULES", "DISTINGUISHES",
"AFFIRMS", "REVERSES"
]
2. Hierarchical Relationship Importance
# Academic papers - prioritize authorship and citations
MVR_HIGH_VALUE_RELATIONSHIPS=[
"AUTHORED", "CITED_BY", "BUILDS_ON",
"CONTRADICTS", "SUPPORTS"
]
3. Temporal or Confidence-Based Filtering
# Only recent, high-confidence relationships
MVR_RELATION_MIN_CONFIDENCE=0.8
MVR_EXCLUDE_RELATIONSHIPS_OLDER_THAN="2024-01-01"
In summary, introduction of intelligent relationship filtering transformed relationship embedding from an all-or-nothing approach into a configurable, semantic-first solution. By allowing developers to specify which relationships carry genuine semantic value, the system achieves both better search quality (focus on meaningful facts) and better performance (optimized vector collections).
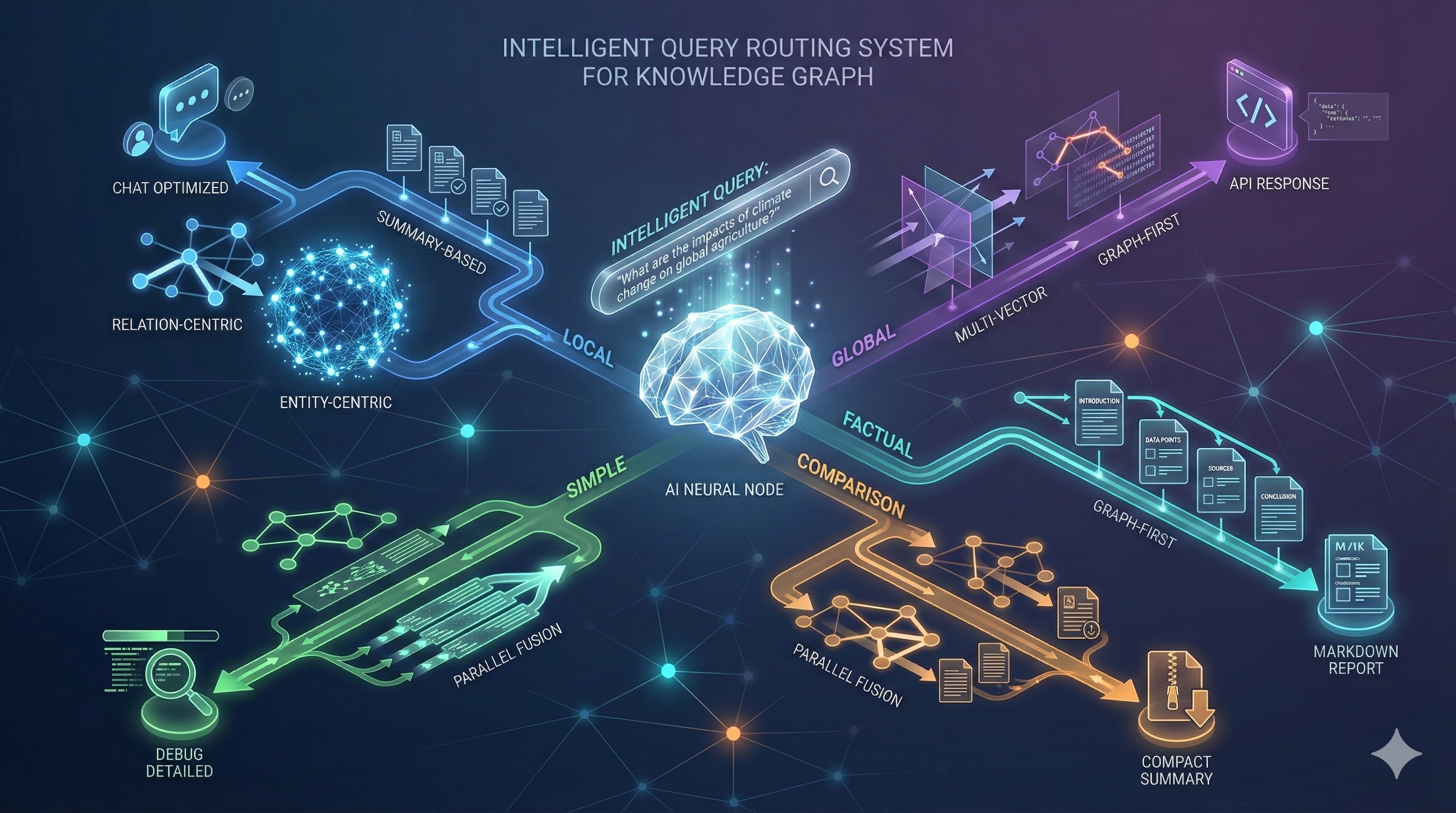
Intelligent Query Routing and Context Retrieval
The transition from multi-vector retrieval capabilities to intelligent query processing requires solving a fundamental challenge: the need to automatically determine the optimal search strategy for diverse query patterns. A query like “Tell me about OpenAI” demands entity-centric search with graph expansion, while “Compare TensorFlow vs PyTorch” requires parallel execution across multiple vector spaces with results combination. Manual strategy selection is impractical as users should not need to understand retrieval architectures to get optimal results.
Our solution is an intelligent query routing system that analyzes incoming queries through a multi-level classification pipeline, determines query intent and type, extracts relevant entities, and automatically selects the optimal retrieval strategy. The system combines pattern recognition, AI-powered semantic analysis, and robust fallback mechanisms to ensure 100% query handling reliability while maintaining sub-500ms response times for 95% of queries.
Multi-Level Classification Architecture
The query router employs a 5-level classification strategy designed for both performance and reliability:
Level 1: Cache Layer provides instant classification for previously analyzed queries, targeting 40-60% hit rate in production. When a query matches a cached entry (within 1-hour TTL), classification completes in under 1ms, eliminating redundant AI processing.
Level 2: Pattern Recognition uses 400+ production-tested regex patterns to handle common query structures without AI invocation. Patterns like tell_me_about, comparison, relationship_who, and simple_fact achieve sub-5ms classification for queries matching clear structural patterns. For example, “Tell me about {entity}” or “Compare {X} vs {Y}” patterns are instantly recognized and classified.
Level 3: Claude AI Analysis handles complex queries requiring semantic understanding. When pattern confidence falls below 0.6, the router invokes Claude API for advanced classification. The AI analyzes query semantics, extracts entities with unlimited recognition capability, identifies entity types (Person, Organization, Location, Technology, Concept, Product, Event), and determines query intent across 6 categories (Comparison Analysis, Analytical Depth, Relationship Exploration, Temporal Analysis, Factual Inquiry, Exploratory Research). Target processing time is under 200ms for entity extraction and 150ms for pattern analysis.
Level 4: Fallback Classification activates when AI classification fails due to API issues, rate limiting, or service unavailability. The system applies heuristic-based classification using query structure analysis, keyword detection, and confidence scoring to ensure queries are never left non-routed.
Level 5: Emergency Classification serves as the final safety net, providing basic LOCAL classification when all other mechanisms fail. This guarantees system reliability even under degraded conditions.
Query Type Classification
The router classifies queries into 5 distinct types, each optimized for different information retrieval patterns:
- LOCAL Queries focus on specific entities or concepts with direct information needs. Examples include “Tell me about OpenAI”, “What is machine learning?”, “Who is Elon Musk?”, or “Describe neural networks”. These queries are routed to entity_centric or mv_first_graph_expand strategies, which prioritize entity-focused search with controlled graph expansion. The system extracts target entities, retrieves entity-centric knowledge subgraphs, and builds focused context around specific concepts.
- GLOBAL Queries require comprehensive search across documents for high-level themes, trends, and summaries. Examples include “Summarize AI research trends”, “What are the main themes in machine learning?”, “List all neural network architectures”, or “Give me an overview of recent breakthroughs”. These queries leverage summary_based or parallel_fusion strategies, searching document summaries and aggregating thematic content across the corpus to provide broad coverage without entity-specific constraints.
- SIMPLE Queries handle direct factual questions with specific answers through single-hop information retrieval. Examples include “Who is the CEO of OpenAI?”, “What is the capital of France?”, “When was GPT-4 released?”, or “Where is Google headquartered?”. The mv_first_graph_expand strategy executes multi-vector search first, then expands with minimal graph traversal to provide precise, factual answers efficiently (~100-120ms).
- COMPARISON Queries require comparative analysis between entities or concepts with parallel information gathering. Examples include “Compare TensorFlow vs PyTorch”, “What’s the difference between GPT-3 and GPT-4?”, or “Contrast machine learning with deep learning”. The parallel_fusion strategy executes searches for both comparison targets simultaneously, retrieves entity and relationship vectors in parallel, applies intelligent result fusion, and structures output for side-by-side analysis.
- FACTUAL Queries demand complex factual information requiring relationship traversal and multi-hop reasoning. Examples include “Who worked with Geoffrey Hinton?”, “How are OpenAI and Microsoft connected?”, “What companies collaborated with Google?”, or “Which researchers founded the field?”. These queries utilize relation_centric or graph_first_mv_rerank strategies, prioritizing relationship search and graph traversal to discover connections before enriching with semantic context.
Retrieval Strategy Execution
Each retrieval strategy implements a specialized approach optimized for its target query type:
- Entity-Centric Strategy focuses on specific entities and their immediate relationships. The execution flow extracts entities from the query using the enhanced entity extraction system, searches entity vectors for semantic matches, retrieves related chunks and relationships from the graph, expands context through graph traversal (typically 1-2 hops), and formats results with entity-focused presentation. This strategy excels for LOCAL queries where users need comprehensive information about specific entities.
- Relation-Centric Strategy prioritizes relationships and connections between entities. The process searches relationship vectors across 14 semantic relationship types (FOUNDED, CREATED, WORKS_FOR, COLLABORATED_WITH, FUNDED_BY, AFFILIATED_WITH, COMPETED_WITH, ACQUIRED, PARTNERED_WITH, INVENTED, LEADS, PUBLISHED, AUTHORED_BY, WORKED_AT), identifies relationship patterns and connection networks, retrieves entity context for relationship endpoints, and structures output with relationship analysis prominent. This strategy is optimal for FACTUAL queries exploring connections and collaborations.
- Summary-Based Strategy provides high-level overviews and thematic analysis. Execution searches document summary vectors for broad semantic matches, aggregates high-level themes and concepts across documents, builds summary-focused context with minimal entity detail, and formats with thematic presentation structure. This strategy is ideal for GLOBAL queries requiring comprehensive thematic understanding without entity-specific depth.
- Multi-Vector First + Graph Expand starts with comprehensive multi-vector search before selective graph expansion. The flow executes parallel searches across entity, relationship, summary, and chunk vectors, identifies key entities from multi-vector results, performs targeted graph traversal to expand context (1-2 hops), combines multi-vector semantic richness with graph precision, and ranks results by relevance. This strategy handles SIMPLE queries efficiently by casting a wide semantic net before focused expansion.
- Graph First + Multi-Vector Rerank inverts the approach by starting with graph precision and enhancing with semantic depth. The process executes graph search for factual precision and entity relationships, performs multi-vector search for semantic context enrichment, applies VoyageAI rerank-2 for optimal result ordering (adds 500-2000ms but significantly improves relevance), and combines graph structural precision with semantic understanding. This strategy excels for FACTUAL queries requiring precise information with semantic context validation.
- Parallel Fusion Strategy executes multiple search strategies simultaneously and intelligently fuses results. The execution launches entity, relationship, and summary searches in parallel, aggregates results from multiple vector spaces, applies intelligent fusion algorithms considering relevance scores, entity overlap, and relationship connections, ranks by multi-dimensional relevance (semantic similarity, entity centrality, relationship strength), and structures output for comprehensive analysis. This strategy is optimal for COMPARISON queries and complex analytical questions requiring information synthesis across multiple dimensions.
Entity Extraction and Enhancement
A critical component of intelligent routing is the enhanced entity extraction system powered by Claude AI. The system identifies entities with unlimited recognition capability, classifies entities into currently used 7 types (Person, Organization, Location, Technology, Concept, Product, Event), extracts aliases and alternative names for robust matching, provides disambiguation context to resolve entity ambiguity, and assigns confidence scores for entity recognition quality.
For example, a query like “Compare Google’s AI research with OpenAI’s approach to language models” extracts:
- Google (Organization, aliases: [“Alphabet”, “Google LLC”], confidence: 0.95)
- AI research (Concept, disambiguation: “artificial intelligence research”, confidence: 0.85)
- OpenAI (Organization, aliases: [“OpenAI LP”], confidence: 0.95)
- language models (Technology, disambiguation: “large language models, LLMs”, confidence: 0.90)
This rich entity representation enables precise vector space searches, accurate graph traversal, and contextual relationship discovery.
Performance and Reliability
The complete query routing and retrieval pipeline achieves:
- Classification Speed: <500ms for 95% of queries (cache: <1ms, pattern: <5ms, Claude AI: <300ms combined)
- Retrieval Performance: 90-200ms for most strategies (excluding optional re-ranking)
- Cache Hit Rate: 40-60% in production environments
- Query Handling: 100% reliability through 5-level fallback architecture
- Entity Recognition: unlimited entities per query
The system includes comprehensive monitoring across classification accuracy by pattern, processing time percentiles (p50, p95, p99), cache hit rates and effectiveness, Claude API usage and error rates, entity extraction accuracy and coverage, and fallback classification frequency for reliability assessment.
Routing Intelligence in Action
Consider how the system handles different query patterns:
- A user asks “Tell me about OpenAI” → Pattern recognition instantly classifies it as LOCAL query with “tell_me_about” pattern → Routes to entity_centric strategy → Extracts “OpenAI” entity → Retrieves entity vectors, relationships, and chunks → Returns focused context.
- A user asks “How are transformers and attention mechanisms related?” → Pattern confidence is low (<0.6) → Claude AI analyzes semantic intent → Classifies it as FACTUAL relationship query → Extracts “transformers” (Technology) and “attention mechanisms” (Concept) → Routes to relation_centric strategy → Searches relationship vectors for BASED_ON, USES, INVENTED connections → Returns relationship-focused context.
- A user asks “Compare the performance of BERT vs GPT architectures” → Pattern recognition identifies “comparison” structure → Classifies it as COMPARISON query → Extracts “BERT” and “GPT” entities → Routes to parallel_fusion strategy → Executes parallel searches for both entities → Combines results with comparison structure → Returns comprehensive comparative analysis in.
This intelligent routing eliminates the need for users to understand retrieval architectures while ensuring each query is processed with the optimal strategy for its information needs. As a result, the system adapts to query intent, scales across diverse query patterns, maintains high performance and reliability, and delivers contextually appropriate results without manual input.
API Usage
The query classification system exposes a REST endpoint for integrating intelligent routing into applications. The /api/query/classify endpoint accepts a query string and returns comprehensive classification results including query type, optimal retrieval strategy, extracted entities, and confidence metrics.
Basic Query Classification
curl -X POST "http://localhost:8000/api/query/classify" \
-H "Content-Type: application/json" \
-d '{
"query": "Tell me about OpenAI"
}'
Response Structure
{
"query": "Tell me about OpenAI",
"classification": {
"query_type": "local", // One of `local`, `global`, `simple`, `comparison`, or `factual`
"retrieval_strategy": "entity_centric", // Optimal strategy from the 6 available options
"confidence": 0.92, // Classification confidence score (0.0-1.0)
"reasoning": "Direct entity reference pattern detected", // Human-readable explanation
"classification_method": "pattern_recognition", // Which level classified the query
"processing_time_ms": 4.2
},
"entities": [ // Array of extracted entities with enhanced metadata
{
"entity_name": "OpenAI",
"entity_type": "Organization",
"aliases": ["OpenAI LP"],
"disambiguation": "AI research company",
"confidence": 0.95
}
],
"suggested_parameters": { // Recommended retrieval parameters based on query type
"top_k": 10,
"max_graph_depth": 2,
"include_relationships": true,
"relationship_types": [
"FOUNDED",
"CREATED",
"LEADS",
"PARTNERED_WITH"
]
},
"metadata": {. // Additional diagnostic information including pattern matches and cache status
"patterns_matched": ["tell_me_about"],
"cache_hit": false,
"fallback_used": false
}
}Comparison Query Example
curl -X POST "http://localhost:8000/api/query/classify" \
-H "Content-Type: application/json" \
-d '{
"query": "Compare TensorFlow vs PyTorch for deep learning"
}'
{
"query": "Compare TensorFlow vs PyTorch for deep learning",
"classification": {
"query_type": "comparison",
"retrieval_strategy": "parallel_fusion",
"confidence": 0.95,
"reasoning": "Comparison pattern detected with multiple entities",
"classification_method": "pattern_recognition",
"processing_time_ms": 3.8
},
"entities": [
{
"entity_name": "TensorFlow",
"entity_type": "Technology",
"aliases": ["TF"],
"confidence": 0.93
},
{
"entity_name": "PyTorch",
"entity_type": "Technology",
"aliases": ["Torch"],
"confidence": 0.93
},
{
"entity_name": "deep learning",
"entity_type": "Concept",
"confidence": 0.88
}
],
"suggested_parameters": {
"top_k": 15,
"parallel_search": true,
"comparison_mode": true
}
}Query Classification Integration Workflow
Applications typically integrate query classification as the first step in the retrieval pipeline:
# Step 1: Classify query
classification_response = requests.post(
"http://localhost:8000/api/query/classify",
json={"query": user_query}
)
classification = classification_response.json()
# Step 2: Execute retrieval with classified strategy
retrieval_response = requests.post(
"http://localhost:8000/api/search/query",
json={
"query": user_query,
"mode": "hybrid_retrieval",
"classification": classification # Pass classification for optimized execution
}
)
# Step 3: Format and present results
context = retrieval_response.json()The classification endpoint provides the intelligence layer that transforms static search into adaptive retrieval, ensuring each query is processed with the optimal strategy based on its semantic intent and structural characteristics.
Context Formatting Options for RAG
Retrieving relevant context from a GraphRAG system is only half the challenge. Presenting that context in a format optimized for its intended consumption is equally critical. Context consumed by a conversational AI requires different formatting than context presented to developers debugging retrieval quality. Similarly, context delivered through REST APIs for an app integration needs different structure than context formatted for human-readable reports. A single formatting approach cannot serve these diverse consumption patterns effectively.
Our solution is a flexible context formatting pipeline that transforms retrieved content into 5 specialized output formats, each optimized for specific use cases. The ContextFormatterService acts as a presentation layer between retrieval and consumption, accepting raw HybridContext objects (containing entities, relationships, chunks, and metadata) and producing formatted output tailored to the consumption context whether by conversational AI, application integration, debugging workflows, quick summaries, or by a comprehensive report.
Chat-Optimized Format structures context for optimal consumption by conversational AI systems. This format prioritizes natural language flow, contextual coherence, and LLM token efficiency. The formatting emphasizes conversational narrative structure with clear entity and relationship presentation, removes technical metadata that clutters LLM context windows, optimizes for 6,000-8,000 token context limits, includes source citations in natural language format, and organizes content hierarchically for coherent AI responses. Here is an example output structure in markdown format:
# Context for: "Tell me about OpenAI"
## Key Information
OpenAI is an artificial intelligence research organization founded in 2015
by Sam Altman, Elon Musk, and other technology leaders. The organization
focuses on developing safe and beneficial AI systems.
## Important Relationships
- **Founded by**: Sam Altman, Elon Musk, Greg Brockman
- **Created**: GPT-4, ChatGPT, DALL-E
- **Partnered with**: Microsoft (strategic partnership and funding)
## Relevant Details
OpenAI transitioned from a non-profit to a "capped-profit" model in 2019
to attract the capital necessary for large-scale AI research. The
organization has released several influential models including the GPT
series and DALL-E image generation system.
**Sources**: 3 documents, 8 text segments
This format removes retrieval metadata, processing times, and technical identifiers, presenting only the information needed for generating natural, accurate responses. Formatting optimized for chat is the default for conversational AI integration.
API Response Format provides structured, machine-readable output for application integration. This format emphasizes programmatic access with clear data structures, complete metadata for downstream processing, standardized field naming and typing, retrieval quality metrics and confidence scores, and JSON-serializable format for REST API responses.
Example output structure:
{
"query": "Tell me about OpenAI",
"context": {
"entities": [
{
"name": "OpenAI",
"type": "Organization",
"description": "AI research organization",
"confidence": 0.95,
"relationships": ["FOUNDED", "CREATED", "PARTNERED_WITH"]
}
],
"relationships": [
{
"source": "Sam Altman",
"type": "FOUNDED",
"target": "OpenAI",
"confidence": 0.92
}
],
"chunks": [
{
"text": "OpenAI is an artificial intelligence research...",
"source_document": "doc_ai_companies_2024.pdf",
"relevance_score": 0.88,
"chunk_id": "chunk_1234"
}
]
},
"metadata": {
"retrieval_strategy": "entity_centric",
"query_type": "local",
"total_results": 8,
"entities_found": 5,
"relations_found": 3,
"processing_time_ms": 152.3,
"confidence": 0.85
},
"sources": [
{
"document_id": "doc_ai_companies_2024.pdf",
"chunks_used": 3,
"relevance": 0.91
}
]
}This format exposes complete retrieval metadata, enables downstream filtering and processing, supports quality assessment and validation, facilitates caching and result aggregation, and provides structured data for application logic. API response format is optimal for building applications that consume GraphRAG context programmatically.
Debug Detailed Format provides detailed diagnostic information for troubleshooting and performance analysis. This format emphasizes complete transparency with performance breakdown by component, strategy execution details and decision paths, error information and warnings, component-level timing and metrics, and raw retrieval results with confidence scores.
Compact Summary Format provides concise, high-level summaries for quick consumption and UI displays. This format emphasizes brevity with single-paragraph summaries, key statistics and metrics only, essential information without verbose details, and optimized for dashboard widgets and previews. Compact summaries sacrifice detail for accessibility.
Markdown Report Format generates comprehensive technical documentation with complete analysis and citation. This format emphasizes thoroughness with executive summary and key findings, detailed technical sections with full context, comprehensive performance metrics, complete source documentation and citations, and professional report structure suitable for sharing. Markdown reports are ideal for technical documentation, research analysis, or stakeholder communication.
API Usage
The context formatting system exposes endpoints for format conversion or retrieval with formatting. Applications can either format existing context objects or execute retrieval and formatting in a single request.
Format Existing Context
curl -X POST "http://localhost:8000/api/context/format" \
-H "Content-Type: application/json" \
-d '{
"query": "Tell me about OpenAI",
"format_type": "chat_optimized"
}'
The formatting layer in GraphRAG system provides the final transformation that ensures retrieved context matches consumption requirements, whether it is feeding conversational AI, powering application logic, enabling debugging workflows, displaying in user interfaces, or generating documentation. This flexibility enables a single GraphRAG system to serve diverse use cases without retrieval-layer modifications.
Conclusion
Part 3 introduced three new capabilities that transformed our GraphRAG system from a multi-vector retrieval foundation into an intelligent query processing pipeline. Configurable semantic relationship selection enables fine-tuned control over which relationship types enter the vector space by prioritizing semantically valuable connections over statistical co-occurrence. Intelligent query routing eliminates manual strategy selection through a multi-level classification system that analyzes query intent, extracts entities with unlimited recognition, and automatically routes queries to optimal retrieval strategies across 5 query types and 6 specialized approaches. Flexible context formatting ensures retrieved content matches consumption requirements through 5 specialized output formats, ranging from conversational AI optimization to comprehensive technical documentation.
Together, these capabilities create an adaptive system that responds intelligently to query patterns: semantic relationship selection determines what enters the retrieval system, query routing determines how queries are processed, and context formatting controls how results are presented. The result is a GraphRAG pipeline that delivers precise, context-aware responses across diverse use cases without requiring users to understand underlying retrieval architectures.
However, our current approach to GLOBAL queries that require comprehensive thematic analysis across all documents relies primarily on document summaries and parallel vector space searches. While effective for many use cases, this approach has limitations when users need to understand high-level themes and conceptual relationships that emerge across large knowledge graphs. For example, a research paper might contain distinct research themes around neural architectures, reinforcement learning, and computer vision, but these topics and relationships aren’t explicitly captured in our current retrieval mechanisms.
In Part 4 of this blog series, I will talk about community/theme detection and community-based GLOBAL search, which allows GraphRAG system to identify and leverage hierarchical community structures within knowledge graphs. We’ll explore how graph algorithms detect natural groupings of interconnected entities, how communities are embedded into dedicated vector spaces for semantic search, and how GLOBAL queries leverage community summaries to provide comprehensive thematic analysis that goes beyond document-level aggregation. This community-aware approach will enable queries like “What are the major research themes in AI?” or “Summarize the main technological trends” to return answers grounded in discovered community structures rather than just document similarities.
