

Part 4 explores new advanced features introduced in GraphRAG by enabling community detection and community-based GLOBAL search, which allows system to identify and leverage hierarchical community structures within knowledge graphs. We’ll explore how graph algorithms in Neo4j detect natural groupings of interconnected entities, how communities are embedded into dedicated vector spaces for semantic search, and how GLOBAL queries leverage community summaries to provide thematic analysis.
Introduction
In Part 3 of this series, we explored how intelligent query routing enables GraphRAG to automatically select optimal retrieval strategies across four vector spaces (entities, relationships, summaries, and chunks) delivering context-aware responses through six specialized retrieval approaches. While this Multi-Vector Retrieval (MVR) system excels at LOCAL queries focusing on specific entities and their immediate connections, GLOBAL queries that seek insights across entire document corpus remained limited to summaries at document level.
Recently, we transformed GLOBAL search capabilities by introducing hierarchical community detection powered by Neo4j’s Graph Data Science (GDS) library. Communities represent natural groupings of interconnected entities within the knowledge graph—clusters of people, organizations, technologies, and concepts that frequently occur together and share semantic relationships. By applying the Louvain algorithm to our entity graph, we detect these communities automatically, generate AI-powered summaries for each community, and embed them into a dedicated fifth vector space for semantic search.
This enabled a fundamentally different approach to GLOBAL queries. Instead of aggregating document summaries, the system now identifies relevant communities, samples their representative entities, and synthesizes insights that span multiple documents while maintaining coherent topical focus. A query like “What are the major AI research themes in my document collection?” no longer returns a flat list of document summaries—it surfaces groups of researchers, organizations, and technologies organized around shared research themes like “transformer architectures,” “reinforcement learning,” or “multimodal AI systems.”.
The implementation introduces two new core services: CommunityService for detection and CommunityEmbeddingService for vector operations plus, a 7th retrieval strategy that seamlessly integrates with our existing hybrid retrieval orchestration service. This architectural approach maintains backward compatibility with all existing conversational AI features while enabling powerful new community-based search through six new REST API endpoints.
In this post, I will explore how community detection works at the graph algorithm level, how AI generates rich community embedding vectors, and how the hybrid retrieval system leverages community structures to deliver superior GLOBAL search results that reveal the thematic organization of your knowledge graph.
Technical Architecture Update
The GraphRAG architecture (see the diagram included into Part 2 of the series ) has been extended to add two new services for community detection and thematic analysis that are integrated with five existing services to support community-based GLOBAL search.
CommunityService – Graph Analytics Foundation
New CommunityService provides the backbone for community detection powered with Neo4j’s Graph Data Science (GDS) library to identify natural groupings within the entity graph. Service supports the following capabilities:
- Neo4j GDS Integration: Louvain algorithm in GDS library is used to detect communities on in-memory graph projections
- Hierarchical Detection: Algorithm is configured to detect multi-level community structures (levels 0-3) with parent-child relationships
- CRUD Operations: New service supports complete lifecycle management for community entities and hierarchies.
- AI-Powered Analysis: Community theme, summary and description are generated using Claude API.
The service creates graph projections from existing Entity nodes and their relationships (such as MENTIONED_WITH, WORKED_AT, etc.), applies the Louvain algorithm with configurable resolution parameters (0.1-5.0), and then structures detected communities hierarchically in Neo4j.
CommunityEmbeddingService – Vector Space Integration
Another new CommunityEmbeddingService allows transforming communities into searchable vector representations which are stored as the 5th vector space collection in ChromaDB. Service supports the following capabilities:
- VoyageAI Integration: Voyage-3 AI model is used to generate embedding vector with 1024 dimensions based on AI-generated Community summary, theme and keywords..
- ChromaDB Management: Generated vectors are stored in the community_embeddings collection with metadata for filtering support. Efficient embedding generation for multiple communities.
- Similarity Search: Community retrieval supports level and size filtering.
Each community is embedded based on its AI-generated theme, summary, keywords, and entity descriptions, enabling semantic search across community structures rather than individual documents.
Enhanced Existing Services
HybridRetrievalService: 7th Retrieval Strategy
New global_with_communities search strategy has been added as the 7th retrieval approach in the GraphRAG orchestration sub-system which searches the community_embeddings collection for thematically relevant communities and then aggregates entities and relationships within matched communities. If communities are not available, it falls back to document summaries.
The enhancement maintains backward compatibility with all six existing strategies while enabling intelligent community-based GLOBAL query processing.
SearchService: Community Search Capabilities
Added support for semantic search across community embedding vectors with metadata filtering by hierarchy level and community size. New method is integrated with existing multi-vector search architecture with community aware result ranking and scoring
ContextFormatterService: Community Context Formatting
Added new method to transform community search results into structured context with community theme, up to 5 entity samples, and hierarchy presentation. Markdown report generation option was enhanced to account for community representation.
QueryRouter: Enhanced Query Classification
Updated Claude AI prompts and classification logic to recognize community based GLOBAL queries, including Community detection patterns in query analysis which yield routing to new global_with_communities search strategy with community aware retrieval.
MultiVectorServiceManager: 5th Vector Collection
Integrated community embedding support into the unified multi-vector management system in GraphRAG, including Community embedding generation or regeneration with force refresh and consistent interface across all five vector collections.
Community Data Flow
New services integration and enhancements in existing service created a 7 step flow from graph structure to searchable embedding vectors:
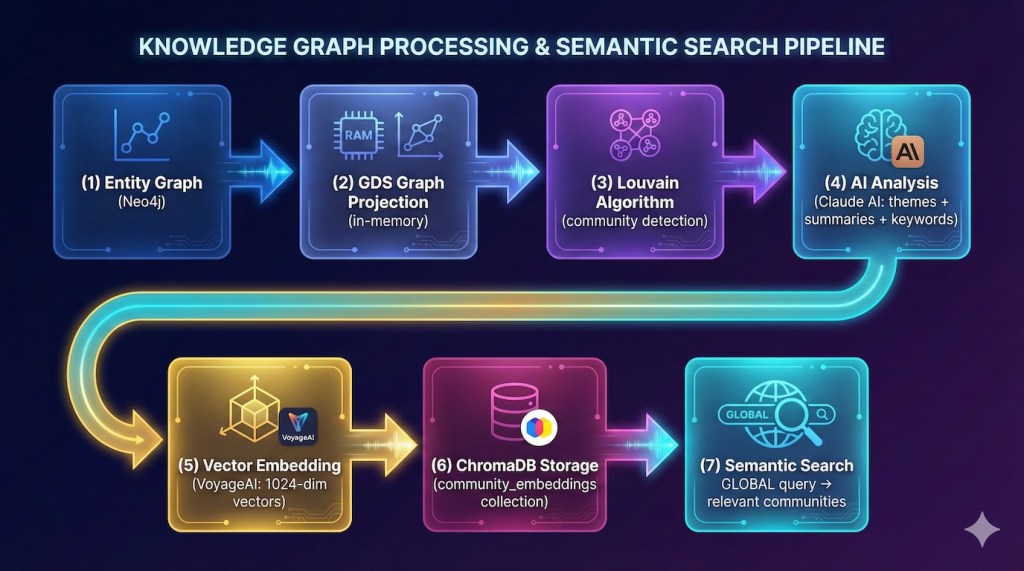
This approach maintains the separation of concerns established in earlier project while adding powerful community-based capabilities that enhance GLOBAL search coherence and thematic organization.
Community Detection
Community detection identifies natural groupings of entities within the knowledge graph—clusters where entities share dense interconnections and weak ties to other clusters. Unlike arbitrary grouping by document or entity type, communities emerge from the actual relationship patterns in your data, revealing thematic structures that span multiple documents.
Community Data Model
To define the community structure and metadata we introduced a comprehensive Pydantic models:
class Community(BaseModel):
"""Core community entity with AI-generated insights"""
id: str # Unique community identifier
level: int # Hierarchy level (0-3)
size: int # Number of member entities
theme: str # AI-generated theme (2-4 words)
summary: str # AI-generated summary (2-3 sentences)
keywords: List[str] # Domain keywords (5-8 keywords)
entity_types: Dict[str, int] # Entity type distribution
modularity: float # Quality metric (0.0-1.0)
created_at: datetime
updated_at: datetime
class CommunityMember(BaseModel):
"""Entity membership in communities"""
entity_id: str
entity_name: str
entity_type: str
aliases: List[str]
description: Optional[str]
class CommunityHierarchy(BaseModel):
"""Parent-child relationships between communities"""
parent_id: str
child_ids: List[str]
level: int
These data models enable rich metadata storage in both Neo4j (graph relationships) and ChromaDB (vector metadata) and thus, supporting sophisticated filtering and search operations.
Graph Projection and Louvain Algorithm
Community detection begins with creating an in-memory graph projection in Neo4j using Graph Data Science (GDS) library. The projection includes Entity nodes connected through five relationship types: MENTIONED_WITH (co-occurrence relationship, SEMANTIC_SIMILARITY (AI-detected semantic relationship), WORKED_AT -(Person and Organization relationship), RELATED_TO (general entity associations), and CONNECTS_TO (cross-document entity connections).
# Graph projection in Neo4j GDS
G = gds.graph.project(
"entity_graph_projection",
["Entity"],
{
"MENTIONED_WITH": {"orientation": "UNDIRECTED"},
"SEMANTIC_SIMILARITY": {"orientation": "UNDIRECTED"},
"WORKED_AT": {"orientation": "UNDIRECTED"},
"RELATED_TO": {"orientation": "UNDIRECTED"},
"CONNECTS_TO": {"orientation": "UNDIRECTED"}
}
)
Next, the Louvain algorithm analyzes this projection to detect communities by maximizing modularity which is a measure of how well-separated communities are from each other. The algorithm iteratively moves nodes between communities to optimize modularity, resulting in natural groupings where intra-community connections are dense and inter-community connections are sparse.
Neo4j Community Graph Structure
Detected communities are persisted in Neo4j as first-class entity node with descriptive metadata and rich relationship modeling:
CREATE (c:Community {
id: "comm_001",
level: 0,
size: 47,
theme: "AI Research Collaboration",
summary: "A cluster of AI researchers...",
keywords: ["machine learning", "neural networks", "transformers"],
modularity: 0.73,
created_at: datetime(),
updated_at: datetime()
})
Relationship Types:
1. HAS_MEMBER – links Community to Entity nodes:
(community:Community)-[:HAS_MEMBER]->(entity:Entity)
2. PARENT_COMMUNITY – creates a hierarchical structure:
(child:Community)-[:PARENT_COMMUNITY]->(parent:Community)
3. SHARES_ENTITIES – connects overlapping communities (Louvain typically, doesn’t create it):
(comm1:Community)-[:SHARES_ENTITIES {count: 3}]->(comm2:Community)
4. RELATED_THEME – AI-detected thematic relationships:
(comm1:Community)-[:RELATED_THEME {similarity: 0.82}]->(comm2:Community)
5. EVOLVED_FROM – tracks community changes over subsequent detection:
(new:Community)-[:EVOLVED_FROM]->(old:Community)
This schema enables complex graph queries like “Find all communities containing Person entities who worked at Technology companies” or “Show me the parent communities for all Climate Science communities.”
Hierarchical Community Generation
The Louvain algorithm can produce hierarchical community structures through recursive application at increasing resolutions:
Level 0 (Coarse): broad thematic communities (10-100+ entities, resolution: 0.5-1.0) for example “Healthcare Technology”, “Climate Research”, “Financial Services”
Level 1 (Medium): sub-themes within broader communities (20-50 entities, resolution: 1.0-2.0) for example: within “Healthcare Technology” community → “Medical Imaging AI”, “Drug Discovery”, “Clinical Diagnostics”
Level 2 (Fine): specific topic clusters (5-20 entities, resolution: 2.0-3.0) for example: within “Medical Imaging AI” community → “Radiology Networks”, “Pathology Systems”, “Diagnostic Tools”
Level 3 (Granular): narrow focus areas (2-10 entities, resolution: 3.0-5.0) for example: within “Radiology Networks” community → “CNN Architectures”, “Transfer Learning”
The system creates `PARENT_COMMUNITY` relationships automatically by detecting entity overlap between levels. A Level 1 community becomes a child of a Level 0 community if they share ≥30% of entities.
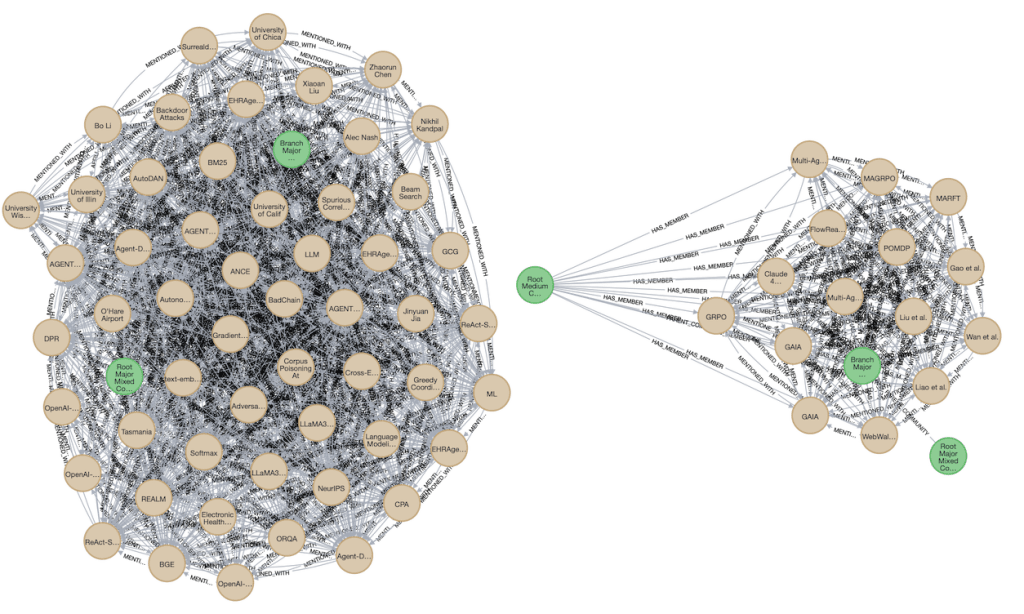
Here is an example of 2- and 3-level hierarchical communities detected in the test repository:
Community Detection Workflow
The end-to-end detection pipeline coordinates multiple services and AI models:
Step 1: Graph Projection Creation – CommunityService queries Neo4j for Entity nodes and relationships and calls on GDS to create in-memory weighted undirected graph.
Step 2: Louvain Algorithm Execution– the algorithm runs iteratively for each hierarchy level (0-3) to identify optimal community assignments based on modularity criteria.
Step 3: Neo4j Community Storage – Community nodes are created in Neo4j with initial metadata. Next, we establish [:HAS_MEMBER] relationships to entities and build [:PARENT_COMMUNITY] hierarchical relationships.
Step 4: AI Theme Analysis – we use Claude to analyze entity names, types, and descriptions within each community. Claude generates concise themes (2-4 words): “AI Safety Research”, “Quantum Computing” and produces summaries (2-3 sentences) explaining community coherence. It also extracts 5-8 relevant keywords representing domain concepts for a community.
Step 5: Vector Embedding Generation – CommunityEmbeddingService constructs rich text by combining theme, summary, keywords, and entity info. It then uses VoyageAI voyage-3 model to generate 1024-dimensional embedding vectors that capture community semantic meaning for similarity search
Step 6: ChromaDB Storage – Community embedding vectors are stored in the dedicated community_embeddings collection. Vector metadata includes level, size, theme, keywords, entity types which allows filtering, like “Find Level 1 communities with >20 members about ‘machine learning'”.
Step 7: Search Integration – HybridRetrievalService was extended to allow routing GLOBAL queries to community search by adding ability to detect community appropriate queries to the QueryRouter.
If AI-based community analysis is enabled (optional), it may take up to 10 seconds for a large community to complete it. Community detection process needs to run periodically hence, always using AI analysis is not a showstopper.
Search and Hybrid Retrieval Integration
To enable community-based search capabilities we extended the hybrid retrieval orchestration service by introducing the 7th retrieval strategy in addition to the existing six strategies. This enhancement enables GLOBAL queries to leverage thematic community structures rather than relying solely on document-level summaries.
Community Similarity Search
New search_communities method in the SearchService provides flexible community retrieval with semantic similarity and metadata filtering:
Core Search Parameters:
async def search_communities(
query: str, # Natural language query
top_k: int = 5, # Number of communities to return
level_filter: Optional[int] = None, # Filter by hierarchy level (0-3)
min_size: Optional[int] = None, # Minimum entity count
max_size: Optional[int] = None, # Maximum entity count
min_modularity: Optional[float] = None # Quality threshold
) -> List[CommunitySearchResult]
Search Process Flow:
- Query Embedding: VoyageAI voyage-3 converts the query into a 1024-dimensional vector
- Vector Search: ChromaDB performs cosine similarity search across community_embeddings collection
- Metadata Filtering: results are filtered by level, size, and quality constraints
- Ranking: matching communities are ranked by similarity score and secondary quality metrics
- Result Enrichment: finally, entity samples and statistics are added from Neo4j
Example Search Query:
# Find large, high-quality Level 0 communities about AI research
results = await search_service.search_communities(
query="artificial intelligence machine learning research",
top_k=5,
level_filter=0,
min_size=30,
min_modularity=0.6
)
# Response structure
[
{
"community_id": "comm_003",
"theme": "Deep Learning Architectures",
"summary": "A cluster of neural network researchers...",
"similarity_score": 0.89,
"size": 47,
"level": 0,
"keywords": ["transformers", "attention", "neural nets"],
"sample_entities": [
{"name": "Attention Mechanism", "type": "Concept"},
{"name": "Vaswani et al.", "type": "Person"},
{"name": "Google Brain", "type": "Organization"}
],
"entity_type_distribution": {"Person": 15, "Organization": 12, "Technology": 20}
}
]
The metadata filtering enables precise control: “Find all Level 1 sub-communities within the Healthcare domain that contain at least 10 Person entities”.
QueryRouter Community Integration
The QueryRouter now recognizes queries appropriate for using communities and routes them to the global_with_communities strategy automatically. The enhanced Claude classification prompt includes community detection patterns:
"""
Analyze this query and select the optimal retrieval strategy:
AVAILABLE STRATEGIES:
1. entity_centric_with_relations (LOCAL): Entity-focused with relationship exploration
2. relation_centric_graph_first (LOCAL): Relationship-focused graph traversal
3. summary_based_parallel (SIMPLE): Quick document summary search
4. multi_vector_balanced (COMPARISON): Multi-collection balanced search
5. chunk_centric_precise (FACTUAL): Precise chunk-level retrieval
6. parallel_fusion_comprehensive (COMPLEX): Comprehensive multi-modal search
7. global_with_communities (GLOBAL): Thematic community-based analysis <-- NEW
QUERY TYPE INDICATORS:
- GLOBAL: "themes", "trends", "overall", "major topics", "common patterns"
- LOCAL: "tell me about [entity]", "how are X and Y related"
- SIMPLE: "what is", "define", "explain"
- COMPARISON: "compare", "difference between", "vs"
- FACTUAL: "when did", "what year", "how many"
Query: {user_query}
"""
The router identifies the following community patterns in use queries to request thematic analysis:
- Pattern 1: Explicit Theme Requests → “What are the main research themes?”
- Pattern 2: Trend Analysis → “What trends emerge across documents?”
- Pattern 3: Topic Clustering → “What major topics are covered?”
- Pattern 4: Domain Overview → “Give me an overview of the AI research landscape”
- Pattern 5: Comparative Themes → “What different approaches exist?”
Routing Decision:
if query_type == "GLOBAL" and community_patterns_detected:
strategy = RetrievalStrategy.GLOBAL_WITH_COMMUNITIES
elif query_type == "GLOBAL":
strategy = RetrievalStrategy.SUMMARY_BASED_PARALLEL # Fallback
else:
# Route to appropriate LOCAL/SIMPLE/COMPARISON/FACTUAL strategy
This ensures GLOBAL queries automatically leverage community structures when available, falling back to document summaries if communities haven’t been detected yet.
Community-Based GLOBAL Query Processing
New _global_with_communities() method in the HybridRetrievalService orchestrates community-based GLOBAL search using the following processing pipeline:
async def _global_with_communities(
self,
query: str,
context: RetrievalContext
) -> RetrievalResult:
"""Execute community-based GLOBAL search strategy"""
# Step 1: Search for relevant communities
communities = await self.search_service.search_communities(
query=query,
top_k=5,
level_filter=0, # Start with top-level communities
min_modularity=0.5
)
# Step 2: Aggregate entities across matched communities
all_entities = set()
for community in communities:
members = await self.community_service.get_community_members(
community_id=community.id
)
all_entities.update(members)
# Step 3: Retrieve entity details and relationships
entity_details = await self.graph_service.get_entities_batch(
entity_ids=list(all_entities)
)
# Step 4: Calculate document coverage
documents = set(entity.document_id for entity in entity_details)
coverage_stats = {
"total_documents": len(documents),
"entities_retrieved": len(all_entities),
"communities_matched": len(communities)
}
# Step 5: Format community-enhanced context
formatted_context = await self.context_formatter.format_global_community_context(
communities=communities,
entities=entity_details,
coverage=coverage_stats
)
return RetrievalResult(
strategy=RetrievalStrategy.GLOBAL_WITH_COMMUNITIES,
context=formatted_context,
metadata={
"communities": [c.dict() for c in communities],
"coverage": coverage_stats
}
)
The fallback logic is used if communities are not detected yet or no communities match the query:
not communities or len(communities) == 0:
# Fallback to document summary approach
return await self._summary_based_parallel(query, context)
This ensures graceful degradation when community data is unavailable.
Community Theme Presentation
New format_global_community_context() method in the ContextFormatterService creates rich, structured presentations of community search results for example, below is an examle of markdown presentation template that at is used to generate a report:
# GLOBAL Analysis: {query}
## Community Overview
Found 5 thematic communities spanning 127 entities across 23 documents.
### Community 1: Deep Learning Architectures (Level 0, 47 entities, Modularity: 0.73)
**Theme Summary:**
A cluster of neural network researchers and organizations focused on transformer
architectures and attention mechanisms. The community represents foundational work
in modern deep learning spanning academic and industry research.
**Key Topics:** transformers, attention mechanisms, neural networks, BERT, GPT
**Representative Entities:**
- **People**: Vaswani et al., Ashish Vaswani, Niki Parmar
- **Organizations**: Google Brain, OpenAI, DeepMind
- **Technologies**: Transformer Architecture, Multi-Head Attention, Positional Encoding
**Document Coverage:** 8 documents
- "Attention Is All You Need" (2017)
- "BERT: Pre-training of Deep Bidirectional Transformers" (2018)
- "Language Models are Few-Shot Learners" (2020)
---
### Community 2: Computer Vision Research (Level 0, 38 entities, Modularity: 0.68)
**Theme Summary:**
Researchers and techniques focused on visual recognition tasks including image
classification, object detection, and semantic segmentation using convolutional
and attention-based architectures.
**Key Topics:** image recognition, CNNs, object detection, semantic segmentation
**Representative Entities:**
- **People**: Kaiming He, Ross Girshick, Shaoqing Ren
- **Organizations**: Facebook AI Research, UC Berkeley
- **Technologies**: ResNet, Faster R-CNN, Mask R-CNN
**Document Coverage:** 6 documents
**Entity Sampling Strategy:**
To keep context manageable, the presentation generation service samples up to 5 representative entities per community using the following pattern:
- Highest-degree entities (entity with most connections)
- Diverse entity types (a representative mix of Person, Organization, Technology, etc.)
- Core community members
This provides a representative snapshot without overwhelming the AI with hundreds of entity names.
Hybrid Retrieval Integration
The community strategy has been integrated with existing six strategies:
| Strategy | Vector Spaces | Graph Queries | Use Case |
|---|---|---|---|
| entity_centric_with_relations | entities, relations | Multi-hop traversal | “Tell me about X” |
| relation_centric_graph_first | relations | Relationship-first | “How are X and Y connected?” |
| summary_based_parallel | summaries | Document metadata | “Quick overview of topic” |
| multi_vector_balanced | All 4 collections | Entity lookup | “Compare X vs Y” |
| chunk_centric_precise | chunks | Minimal graph | “What year did X occur?” |
The orchestration service implements the same interface for all search strategies:
# All strategies use the same orchestrator interface
result = await hybrid_retrieval_service.execute_strategy(
strategy=RetrievalStrategy.GLOBAL_WITH_COMMUNITIES,
query="What are the major AI research themes?",
context=retrieval_context
)
# Consistent result structure regardless of strategy
{
"strategy": "global_with_communities",
"context": "# GLOBAL Analysis...",
"metadata": {
"communities": [...],
"coverage": {...}
},
"performance_metrics": {
"total_time_ms": 180,
"search_time_ms": 150,
"formatting_time_ms": 30
}
}
This enables the conversational AI service to consume community results in the same way as other retrieval strategies.
Community REST API Endpoints
In this section we’ll talk about six new REST API endpoints for community detection, querying, and analysis that were introduced in addition to the existing 36 document and query endpoints.
POST /api/communities/detect – Community Detection Trigger
Allows you to initiate community detection on the current knowledge graph, applying the Louvain algorithm across all hierarchy levels.
curl -X POST "http://localhost:8000/api/communities/detect" \
-H "Content-Type: application/json" \
-d '{
"resolution": 1.0, # (0.1 - 5.0, default: 1.0): Controls community granularity in GDS
"enable_hierarchy": true, # {default: true) enable hierarchy detection
"max_levels": 3, # (0 - 3, default: 3): Maximum hierarchy depth
"min_community_size": 5, # (2 - 100, default: 5): Minimum entities per community
"enable_ai_analysis": false, # (default: false) triggers Claude AI analysis for themes,...
"force_refresh": false, # (default: false) Re-detect existing communities
"generate_embeddings": true # (default: true) Create community embedding vectors
}'
Using AI analysis to generate community theme, summary or description is a per-requisite to allow good quality embedding vectors for GLOBAL search. For a community with 100+ entities, it may take 10+ seconds to process it with AI enabled therefore, if your priority is to check what types of communities and hierarchies exist in the repository, you can run detection with AI disabled. The latter will generate names and themes.
In response you will get a list of detected communities with detailed in formation, for example:
{
"communities": [
{
"id": "community_739_L3",
"name": "L3 Major Mixed Community (449 entities)",
"theme": "Global AI Ecosystem",
"level": 3,
"size": 449,
"entities": [],
"entity_ids": [
"entity_block_organization_1765112941",
...
],
"relationships": [],
"summary": "The global AI ecosystem is a dynamic network of technology companies, research organizations, AI models, and key innovators working to develop, regulate, and advance artificial intelligence technologies. This community represents the cutting edge of AI research, development, and implementation across multiple sectors and geographies, with a focus on transformative technological capabilities and responsible innovation.",
"keywords": [
"Artificial Intelligence",
"Machine Learning",
"Technology Innovation",
"AI Safety",
"Generative AI",
"Digital Transformation",
"Computational Intelligence"
],
"description": "This community represents a comprehensive and interconnected landscape of artificial intelligence and technology innovation, encompassing organizations, products, technologies, research initiatives, and key stakeholders driving the advancement of AI. The ecosystem spans multiple domains including financial services, technology platforms, research institutions, AI safety initiatives, and regulatory frameworks, with a strong emphasis on generative AI, machine learning, and the ethical development of intelligent systems.",
"documents": [],
"document_count": 0,
"chunks": [],
"confidence_score": 0.8,
"modularity_score": 0,
"density": 0,
"parent_community_id": null,
"child_community_ids": [
"739_L2"
],
"status": "ready",
"has_embedding": true,
"embedding_id": "community_community_739_L3",
"detection_algorithm": "louvain",
"resolution": 1,
"created_at": "2025-12-16T22:05:34.355224",
"updated_at": "2025-12-16T22:05:34.355243"
}, ...
GET /api/communities – Community Listing with Pagination
Retrieves a list of existing communities with filtering, pagination, and sorting options.
curl -X GET "http://localhost:8000/api/communities?\
level=0&\ # (0 - 3, optional): Filter by hierarchy level (0-3)
min_size=20&\ # (optional): Minimum entity count
max_size=50&\ # (optional): Maximum entity count
min_modularity=0.6&\ # (0.0 - 1.0, optional): Minimum quality score
sort_by=size&\ # (sdefault: "size"): Sort field (size, modularity, level, created_at)
sort_order=desc&\ # (default: "desc"): Sort direction (asc, desc)
page=1&\ # (default: 1): Page number
page_size=10" # (default: 20): Results per page
GET /api/communities/{id} – Detailed Community Information
This endpoint retrieves comprehensive details for a specific community:
curl -X GET "http://localhost:8000/api/communities/comm_003?\
include_entities=true& # (default: true): Include entity samples
max_entities=10&\ # (default: 10): Maximum entities to return
include_children=true" # (default: true): Include child communities
Response includes entity samples and relationships, for example:
{
"id": "community_739_L1",
"name": "Branch Major Mixed Community (449 entities)",
"theme": "Global AI Ecosystem",
"level": 1,
"size": 449,
"entities": [
...
{
"id": "entity_gpt-4o_technology_1765113942",
"name": "GPT-4o",
"normalized_name": "gpt-4o",
"type": "Technology",
"confidence": 0.95,
"aliases": [
"gpt4o",
"GPT-4O",
"OpenAI model",
"GPT-4o",
"GPT4o",
"GPT 4o",
"gpt-4o-mini"
],
"description": "Large language model in the GPT series"
},
...
],
"relationships": [...],
"summary": "The global AI ecosystem is a dynamic network of organizations, technologies, and stakeholders driving the development and governance of artificial intelligence. This community represents a complex interplay of technological innovation, research, product development, and regulatory considerations in the emerging field of advanced AI systems.",
"keywords": [
"Artificial Intelligence",
"Machine Learning",
"Technology Innovation",
"AI Governance",
"Generative AI",
"Computational Infrastructure",
"Digital Transformation"
],
"description": "This community represents a comprehensive and interconnected landscape of artificial intelligence development, spanning technology companies, research institutions, regulatory bodies, and innovative AI products. The ecosystem encompasses organizations actively developing advanced AI technologies, exploring machine learning models, establishing regulatory frameworks, and pushing the boundaries of generative AI, computational infrastructure, and intelligent systems. Key players include major technology companies like OpenAI, Google, Meta, Amazon, and emerging AI-focused startups, all contributing to the rapid evolution of artificial intelligence across multiple domains.",
"documents": [],
"document_count": 0,
"chunks": [...],
"confidence_score": 0.8,
"modularity_score": 0,
"density": 0,
"parent_community_id": "739_L2",
"child_community_ids": [
"55_L0",
"1414_L0",
"25_L0",
"739_L0",
"2124_L0"
],
"status": "ready",
"has_embedding": true,
"embedding_id": "community_community_739_L1",
"detection_algorithm": "louvain",
"resolution": 1,
"created_at": "2025-12-16T22:01:17.537678",
"updated_at": "2025-12-16T22:01:17.537703"
}
Note, entities, their aliases and descriptions; relationships as well as community summaries, a list of keywords, and description are extracted using Claude AI.
POST /api/communities/global-summary – GLOBAL Search with Communities
This endpoint executes community-based GLOBAL search queries, leveraging thematic structures for comprehensive analysis.
curl -X POST "http://localhost:8000/api/communities/global-summary" \
-H "Content-Type: application/json" \
-d '{
"query": "What are the major AI research themes in my documents?",
"top_k_communities": 5, # (default: 5): Number of communities to retrieve
"level_filter": 0, # (optional): Hierarchy level constraint
"min_modularity": 0.5, # (float, optional): Community quality threshold
"include_entity_samples": true, # (default: true): Include representative entities
"output_format": "markdown" # (default: "markdown"): response format (markdown, json, api)
}'
Response in markdown form will looks like:
# GLOBAL Analysis: Major AI Research Themes
## Community Overview
Found 5 thematic communities spanning 127 entities across 23 documents.
### Community 1: Deep Learning Architectures (47 entities, Modularity: 0.73)
**Theme Summary:**
A cluster of neural network researchers focused on transformer architectures...
**Key Topics:** transformers, attention mechanisms, neural networks, BERT, GPT
**Representative Entities:**
- **People**: Vaswani et al., Ashish Vaswani, Niki Parmar
- **Organizations**: Google Brain, OpenAI, DeepMind
- **Technologies**: Transformer Architecture, Multi-Head Attention
**Document Coverage:** 8 documents
---
[Additional communities...]
GET /api/communities/{id}/entities – Community Member Entities
This endpoint retrieves all entities belonging to a specific community with detailed metadata.
curl -X GET "http://localhost:8000/api/communities/comm_003/entities?\
entity_type=Person&\ # (optional): Filter by entity type
sort_by=degree&\ # (default: "degree"): Sort field (degree, name, type)
dort_oder=desc&\. # (default: "desc"): Sort direction
page=1&\ # (default: 1): Page number
page_size=20" # (default: 50): Results per page
GET /api/communities/statistics – Community Analytics
This endpoint provides a comprehensive statistics and analytics across all detected communities.
curl -X GET "http://localhost:8000/api/communities/statistics"
Response includes summary information about detected communities, their average size, quality, document coverage, and hierarchies.
Conclusion
Introduction of hierarchical community detection powered by Neo4j’s Graph Data Science library transformed how GraphRAG handles GLOBAL queries. Rather than relying solely on document-level summaries, the system now can identify natural thematic clusters within entity groups in the knowledge graph that frequently appear together and share semantic relationships across multiple documents. This shift from document-centric to theme-centric analysis delivered more coherent, insightful responses to queries like “What are the major research themes?” or “What trends emerge across my document collection?”.
GraphRAG now includes two new Community and CommunityEmbedding services that are integrated into existing infrastructure to add the 5th vector collection (community_embeddings) and enable the 7th retrieval strategy (global_with_communities). Changes in the architecture maintain the same design pattern: separation of concerns between detection and embedding, Pydantic data models, intelligent fallback logic, and robust REST APIs with full validation and monitoring.
The six new REST API endpoints allow building complex retrieval applications on the GraphRAG platform. From triggering detection with configurable parameters (POST /api/communities/detect) to executing sophisticated GLOBAL searches (POST /api/communities/global-summary), the API interface enables rich integration scenarios including analytics dashboards, automated theme monitoring, and intelligent content navigation systems.
Looking Ahead: Schema-Driven Ingestion
While Parts 1-4 of this series focused on processing unstructured documents (PDFs, web pages) through AI-powered text extraction and entity recognition, real-world GraphRAG deployments often need ability to ingest structured data from external systems, such as databases, ERP or CX apps. In Part 5 we will talk about a schema-driven ingestion pipeline that bridges this gap, enabling GraphRAG system to process structured documents by combining deterministic (defined by the schema) with probabilistic (AI analysis) steps.
This approach delivers the best of both worlds. For a support ticket, deterministic processing ensures the ‘customer_name’ field always created Organization node and ‘assigned_to’ field always creates a correct ASSIGNED_TO relationship to a relevant Person entity, while probabilistic AI analysis of the ticket description discovers mentions of technologies, related tickets, or affected systems that aren’t captured in structured fields.
Stay tuned to learn how we extended GraphRAG beyond articles or web pages processing into the realm of structured data integration the final piece for building an intelligent platform that synthesize insights across your entire information ecosystem.
Read the complete GrapRAG series:
