

This blog describes a Python application built using LangChain and LangGraph frameworks for testing agentic workflow design patterns such as Chaining, Routing, or Reflection. The application currently implements 10 AI agent patterns, each with several ore-configured representative use cases that you can run using OpenAI GPT, Anthropic Claude, or Google Gemini LLM models for comparison.
Introduction
The rise of Large Language Models (LLMs) over last 3 years has fundamentally changed how we build software by allowing you to utilize AI agents that can not only execute tasks without relying on preset workflows, but also learn from that to improve over time. There is an abundance of blogs and YouTube channels with demos of various AI agents. But moving from impressive demos to AI systems ready for real-life production use requires more than just API calls to GPT-4 or Claude LLM. It requires you to build agent’s workflow following relevant design patterns, called agentic workflow design patterns to enable AI to reason, plan, collaborate, and improve over time. That is similar to building software following well-established software design patterns described in the book “Design Patterns: Elements of Reusable Object-Oriented Software” was published in 1994 by Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides.
What are AI Agents and Agentic Workflows?
An AI agent is more than an AI chat-bot. It’s a software system that can break down complex tasks posed to it into manageable steps and then use tools and external resources as relevant for each step to execute the task. Agent can maintain context and use memory across multiple interactions with a user as required to complete tasks. It can collaborate with other agents, self-critique its work or adapt and improve its actions based on feedback from agents or users.
Agentic workflows are the design patterns that make this possible. Just as software engineers use design patterns like Factory, Observer, or Strategy to solve recurring problems, agentic workflows provide proven solutions like Routing, Reflection, or Planning for common AI challenges.
Why Design Patterns Matter
Without structured patterns, AI applications become brittle and unpredictable. Consider these real-world challenges:
- Code generation: A single LLM call might produce buggy code. A Reflection pattern where one model generates and another critiques produces more reliable results.
- Customer service: Routing every query to a general-purpose agent is inefficient. A Routing pattern classifies requests and delegates to specialized handlers.
- Research analysis: Processing a paper sequentially is slow. A Parallelization pattern runs summary, question generation, and key term extraction concurrently.
Why Testing Framework
I found that most discussions of agentic patterns are theoretical. I can read a blog or watch YouTube video, but neither could answer me: How do these patterns perform in practice? Which LLM models (OpenAI, Anthropic, Google) work best for each pattern? How do you actually implement them?
Hence I decided to build a practical testing framework that currently implements 10 core agentic patterns using LangChain and LangGraph libraries, with the ability to run and compare agents across different models. Python application code is available on GitHub.
The Testing Framework
Why LangChain and LangGraph?
Building agentic workflows from scratch means wrestling with LLM API differences, managing conversation history, implementing state machines, and handling tool calls. Agent frameworks like LangChain or CrewAI abstract these complexities.
LangChain library provides agent foundation:
- Model abstraction – allows switching between OpenAI GPT, Anthropic Claude, and Google Gemini with a single interface
- LCEL (LangChain Expression Language) – allows composing workflow chains with intuitive syntax:
chain = prompt | llm | parser - Tool integration – a decorator-based function calling that works across tool providers
- Memory primitives – built-in conversation buffers and history management tools
LangGraph library extends LangChain by adding advanced agent capabilities:
- State machines – allows defining complex workflows as graphs with nodes (tasks) and edges (workflow routes
- Multi-agent orchestration – allows coordinating sequential, parallel, or debate-style agents collaboration
- Persistence – provides InMemoryStore class to allow using semantic, episodic, or procedural memory
- Conditional routing – provides support for dynamic workflow paths based on agent decisions
Framework Architecture
The testing framework follows a consistent structure that makes patterns easy to implement, run, and compare.
ModelFactory – Multi-Provider Abstraction
A central factory for creating LLM instances from any provider:
# Automatically routes to correct provider based on name
llm = ModelFactory.create("gpt-4o") # OpenAI
llm = ModelFactory.create("claude-sonnet-4-5") # Anthropic
llm = ModelFactory.create("gemini-2.5-flash") # Google
The factory handles API keys, default parameters such as temperature or max_tokens, and provider-specific configurations.
Pattern Folder Structure Convention
Implementation of every agentic pattern follows the same directory structure:
patterns/pattern_name/
├── config.py # Pattern-specific configuration
├── run.py # Implementation and CLI entry point
└── __init__.py # Public API exports
Each run.py implements two key functions:
- run() – execute the design pattern with a single model (or multiple for multi-role patterns)
- compare_models() – run across multiple models and compare results
OutputWriter – Standardized Logging
All results are automatically logged to a file in the experiments/results/ folder with timestamp and pattern name added to the file name:
from agentic_patterns.common import create_writer
writer = create_writer("pattern_name")
writer.write_result(model_name, input_data, result)
writer.write_comparison(models, input_data, results)
This makes it easy to compare how GPT-4, Claude, and Gemini perform on the same task.
Running Design Patterns
Any agentic design pattern can be run from CLI or imported programmatically:
# CLI: Run with default model
uv run src/agentic_patterns/patterns/chaining_01/run.py
# CLI: Specify model
uv run src/agentic_patterns/patterns/reflection_04/run.py gpt-4o
# Python: Programmatic usage
from agentic_patterns.patterns.reflection_04 import run
result = run(creator_model='gpt-4o', critic_model='claude-sonnet-4-5')
Agentic Design Patterns
This section explores 10 core design patterns that I implemented so far (plus, RAG patterns that has been used in other projects), organized by complexity. For complete implementation details, see my GitHub repository.
Pattern Selection Guide
Before diving into individual patterns, you can use a decision tree below to identify which pattern fits your use case:
START: What is your primary challenge?
│
├─► "Task has multiple sequential steps"
│ └─► CHAINING (Pattern 1)
│
├─► "Different request types need different handling"
│ └─► ROUTING (Pattern 2)
│
├─► "Multiple independent subtasks can run simultaneously"
│ └─► PARALLELIZATION (Pattern 3)
│
├─► "Output quality needs iterative improvement"
│ │
│ ├─► "Need automated self-correction"
│ │ └─► REFLECTION (Pattern 4)
│ │
│ └─► "Need structured review with scoring"
│ └─► GOAL SETTING & MONITORING (Pattern 10)
│
├─► "Agent needs external data or capabilities"
│ └─► TOOL USE (Pattern 5)
│
├─► "Complex task needs decomposition and strategic execution"
│ └─► PLANNING (Pattern 6)
│
├─► "Multiple specialized perspectives needed"
│ └─► MULTI-AGENT COLLABORATION (Pattern 7)
│
├─► "Need to remember context across interactions"
│ └─► MEMORY MANAGEMENT (Pattern 8)
│
├─► "Agent should autonomously optimize its performance"
│ └─► LEARNING & ADAPTING (Pattern 9)
│
└─► "Need to ground responses in external documents"
└─► RAG (Pattern 11 - separate project)
Foundation Patterns (1-3) – Building Blocks
Design patterns in this category form the basis for creating more complex agentic workflows.
1. Chaining – Sequential Processing Pipeline
The Pattern: Instead of using a single LLM call for a complex problem, break it down into several simpler steps which will be resolved by a sequence of multiple LLM calls (chain), where output of each step feeds the next step input.
How It Works: Pipeline chain is defined using LangChain Expression Language (LCEL) syntax:
chain = extraction_chain | transform_chain | generation_chain
result = chain.invoke({"input": user_text})
Sample Use Case: Agent analyses product order received from a user:
- Step 1: Extract technical specifications from user description
- Step 2: Transform specs into required structured format
- Step 3: Generate implementation recommendations based on spec documentation
Why It Matters: Most real life problems are complex and require multiple processing steps to provide solution. Applying Chaining pattern makes this explicit and testable.
Trade-offs and Considerations:
| Advantage | Disadvantage |
|---|---|
| Clear separation of concerns | Each step adds API latency |
| Easier debugging (inspect intermediate outputs) | Errors in early steps cascade |
| Specialized prompts per step | Higher token costs (N calls vs. 1) |
| Testable individual components | Over-decomposition adds complexity |
Latency Impact: A 3-step chain incurs 3× the latency of a single call. For latency-sensitive applications, you should balance decomposition granularity against response time requirements.
Error Handling Strategy: Consider adding validation between steps to catch errors early:
# Chain with intermediate validation
def validated_chain(input_data):
# Step 1: Extract
specs = extraction_chain.invoke(input_data)
if not validate_specs(specs):
return {"error": "Extraction failed validation"}
# Step 2: Transform
structured = transform_chain.invoke({"specs": specs})
if not validate_structure(structured):
return {"error": "Transform produced invalid structure"}
# Step 3: Generate
return generation_chain.invoke({"data": structured})
When NOT to Use Chaining Pattern:
- Simple tasks that a single well-crafted prompt can handle
- When latency is critical and steps cannot be parallelized
- When intermediate outputs don’t provide debugging value
2. Routing – Intent-Based Delegation
The Pattern: Complex problems often cannot be handled by a single sequential workflow. The Routing pattern provides a solution by introducing conditional logic into agentic workflow for choosing next step for a specific task. It allows the system to analyze incoming requests to determine a task nature, classify tasks, and then route them to specialized agents for handling.
How It Works: A coordinator LLM agent analyzes the request and then selects the appropriate handler agent:
from langchain_core.runnables import RunnableBranch
router = RunnableBranch(
(lambda x: "booker" in x["category"], booking_handler),
(lambda x: "info" in x["category"], info_handler),
unclear_handler # default
)
Sample Use Case: Customer service automation – coordinator / router agent analyzes incoming requests to determine which specialist handler should process it:
- Booking requests → route to Booking agent if incoming request requires service booking
- Information queries → route to FAQ agent if incoming request is a question
- Unclear requests → route to Human if incoming request is not classified (escalation)
Why It Matters: General-purpose agents are often inefficient in handling specific requests. Routing increases efficiency by enabling specialization.
Classification Approaches:
There are several ways to implement the classification step, each with trade-offs:
| Approach | Speed | Accuracy | Best For |
|---|---|---|---|
| Keyword matching | Fast (no LLM call) | Low | Obvious, distinct categories |
| LLM classification | Slower (+1 API call) | High | Nuanced, overlapping categories |
| Embedding similarity | Medium | Medium-High | Large number of categories |
| Hybrid | Medium | High | Production systems |
Hybrid Classification Example:
def classify_request(request: str) -> str:
# Fast path: keyword matching for obvious cases
request_lower = request.lower()
if any(word in request_lower for word in ["book", "reserve", "schedule"]):
return "booking"
if any(word in request_lower for word in ["cancel", "refund"]):
return "cancellation"
# Slow path: LLM for ambiguous cases
return llm_classifier.invoke(request)
Handling Edge Cases:
Multi-Intent Requests: “Book a flight to Paris and tell me about visa requirements”:
# Option A: Primary intent routing with queue
def route_multi_intent(request: str):
intents = extract_all_intents(request) # Returns: ["booking", "info"]
primary_result = handlers[intents[0]].invoke(request)
# Queue secondary intents for follow-up
for intent in intents[1:]:
queue_followup(intent, request)
return primary_result
# Option B: Split and route each part
def route_split(request: str):
sub_requests = split_request(request)
results = [handlers[classify(sub)].invoke(sub) for sub in sub_requests]
return combine_results(results)
Confidence Thresholds: Escalate to human assistant when uncertain:
CLASSIFICATION_PROMPT = """
Classify this customer request. Return JSON with:
- category: one of [booking, info, complaint, unclear]
- confidence: 0.0 to 1.0
Request: {request}
"""
def route_with_confidence(request: str):
result = classifier.invoke(request)
if result["confidence"] < 0.7:
return escalate_to_human(request)
return handlers[result["category"]].invoke(request)
Sample of Production Classification Prompt:
CLASSIFICATION_PROMPT = """
You are a customer service request classifier. Analyze the request and determine
the most appropriate handling category.
Categories:
- BOOKING: Requests to make, modify, or inquire about reservations (flights, hotels, cars)
- INFO: Questions about policies, destinations, requirements, or general information
- COMPLAINT: Issues with existing services, requests for refunds, or expressions of dissatisfaction
- URGENT: Safety concerns, stranded travelers, or time-sensitive emergencies
- UNCLEAR: Cannot determine intent or request is ambiguous
Request: {request}
Respond with exactly one category name and a brief justification:
Category: <category>
Reason: <one sentence explanation>
"""
When NOT to Use Routing Pattern:
- All requests can be handled by a single general-purpose agent
- Categories overlap significantly (consider hierarchical routing instead)
- Classification overhead exceeds the benefit of specialization
3. Parallelization – Concurrent Execution
The Pattern: Resolving complex problems often require completing multiple sub-tasks that can be executed simultaneously, rather than sequentially. The Parallelization pattern involves executing multiple independent LLM agent chains concurrently to reduce overall latency and then synthesize results as required to solve the problem.
How It Works: Using RunnableParallel object in LangChain with asynchronous execution:
parallel_chains = RunnableParallel(
summary=summary_chain,
questions=questions_chain,
key_terms=key_terms_chain
)
result = await parallel_chains.ainvoke({"topic": topic})
Sample Use Case: Peer review of a research paper:
- Parallel execution: Peer agents generate summary, questions, and key terms simultaneously
- Synthesis: Combine generated reviews into a comprehensive paper critique
Why It Matters: Reduces paper review latency by Nx where N is the number of peers and provides multiple perspectives on the research paper.
Understanding Concurrency vs. Parallelism:
An important distinction for LLM applications:
- Concurrency (what we achieve using this pattern): Multiple tasks in progress simultaneously via async I/O. While waiting for one API response, we can initiate other requests.
- True parallelism: Would require multiple CPU cores executing simultaneously (not typical for I/O-bound LLM calls).
The latency reduction comes from overlapping API wait times, not CPU parallelism. If each LLM call takes 2 seconds, three parallel calls still complete in ~2 seconds (not 6).
Sequential (6 seconds total):
[Call 1: 2s][Call 2: 2s][Call 3: 2s]
Concurrent (2 seconds total):
[Call 1: 2s ]
[Call 2: 2s ]
[Call 3: 2s ]
Synthesis Strategies:
After parallel execution, you need to combine results. Choose based on your use case:
| Strategy | Description | Best For |
|---|---|---|
| Aggregation | Combine all outputs into single document | Research summaries, reports |
| Voting | Multiple agents answer same question, majority wins | Factual queries, classification |
| Weighted Merge | Assign confidence scores, prioritize higher confidence | When agent reliability varies |
| Structured Merge | Each agent fills different fields of output schema | Multi-aspect analysis |
Aggregation Example:
synthesis_prompt = ChatPromptTemplate.from_template("""
Synthesize these parallel analysis results into a coherent report:
Summary Analysis:
{summary}
Key Questions Generated:
{questions}
Important Terms Identified:
{key_terms}
Create a unified analysis that integrates all perspectives.
""")
full_chain = parallel_chains | synthesis_prompt | llm | StrOutputParser()
Voting Example:
synthesis_prompt = ChatPromptTemplate.from_template("""
Synthesize these parallel analysis results into a coherent report:
Summary Analysis:
{summary}
Key Questions Generated:
{questions}
Important Terms Identified:
{key_terms}
Create a unified analysis that integrates all perspectives.
""")
full_chain = parallel_chains | synthesis_prompt | llm | StrOutputParser()
Voting Example:
# Three agents answer the same factual question
parallel_voters = RunnableParallel(
agent1=factual_chain,
agent2=factual_chain,
agent3=factual_chain
)
def majority_vote(results: dict) -> str:
answers = [results["agent1"], results["agent2"], results["agent3"]]
return max(set(answers), key=answers.count)
result = await parallel_voters.ainvoke({"question": question})
final_answer = majority_vote(result)
Error Handling in Parallel Execution:
Parallel chains can partially fail. You should handle such failures gracefully:
async def run_with_fallbacks(topic: str):
try:
results = await parallel_chains.ainvoke(
{"topic": topic},
return_exceptions=True # Returns exceptions instead of raising
)
except Exception as e:
return {"error": str(e)}
# Process results, handling any that failed
processed = {}
for key, value in results.items():
if isinstance(value, Exception):
processed[key] = f"[Failed: {type(value).__name__}]"
logger.warning(f"Chain {key} failed: {value}")
else:
processed[key] = value
return processed
When NOT to Use Parallelization Pattern:
- Tasks have dependencies (output of A is input to B)
- Order of execution matters for correctness
- Rate limits would be exceeded by concurrent requests
- Combined token usage exceeds context window for synthesis
Enhancement Patterns (4-5) – Adding Intelligence
The foundation patterns enable agents to be efficient, fast, and flexible when resolving complex problems. However, even sophisticated workflows may not help agent to handle incoming request correctly, if task understanding by the agent is not accurate or agent is missing information required to give correct answer. Design patterns in this group allow making agents more capable in handling complex problems through evaluating its own work and iterating to refine task understanding; or using relevant tools to obtain missing data.
4. Reflection – Iterative Improvement Through Critique
The Pattern: Reflection pattern offers a solution for self-correction and refinement by establishing a feedback loop where one LLM model generates output, and then another model evaluates it against predefined criteria to allow the first model to revise output based on the received feedback. The iterative process progressively enhances the accuracy and quality of the final result.
How It Works: Using dual-model approach with specific roles defined for each AI agent:
# Generate initial solution
code = creator_llm.invoke(task_prompt)
# Critique the solution
critique = critic_llm.invoke(f"Review this code: {code}")
# Revise based on feedback
improved = creator_llm.invoke(f"Improve based on: {critique}")
Sample Use Case: Code generation on request with generated code review:
- Creator (GPT-4o): Generates Python function based on a user request
- Critic (Claude Sonnet): Reviews generated code for bugs, style, or edge cases support
- Creator: Revises the code based on received feedback
Why It Matters: Single-pass code generation is often flawed. Using Reflection design pattern allows catching errors and improving code quality and style.
Framework Feature: Application supports using different models for creator and critic roles to leverage model-specific strengths.
Iteration Control Strategies:
Deciding when to stop iterating is crucial for both quality and cost of using Reflection:
| Strategy | Description | Pros | Cons |
|---|---|---|---|
| Fixed iterations | Always run N cycles | Predictable cost/time | May over/under-iterate |
| Quality threshold | Stop when grade ≥ target | Efficient | Requires quantifiable metrics |
| Diminishing returns | Stop when delta improvement < ε | Balances quality/cost | Needs improvement tracking |
| Critic consensus | Stop when no issues found | Quality-focused | May never converge | |
Implementation with Multiple Strategies:
def reflection_loop(task: str, max_iterations: int = 5,
quality_threshold: float = 0.9,
min_improvement: float = 0.05):
current_output = creator_llm.invoke(task)
previous_score = 0.0
for i in range(max_iterations):
# Get structured critique with score
critique = critic_llm.invoke(f"""
Review this output and provide:
1. Quality score (0.0 to 1.0)
2. List of issues (empty if none)
3. Specific improvement suggestions
Output: {current_output}
""")
current_score = extract_score(critique)
issues = extract_issues(critique)
# Strategy 1: Quality threshold reached
if current_score >= quality_threshold:
return current_output, f"Reached quality threshold at iteration {i+1}"
# Strategy 2: No issues found (critic consensus)
if not issues:
return current_output, f"No issues found at iteration {i+1}"
# Strategy 3: Diminishing returns
improvement = current_score - previous_score
if i > 0 and improvement < min_improvement:
return current_output, f"Diminishing returns at iteration {i+1}"
# Continue improving
current_output = creator_llm.invoke(f"""
Improve this output based on feedback:
Current output: {current_output}
Feedback: {critique}
""")
previous_score = current_score
return current_output, f"Reached max iterations ({max_iterations})"
Designing Effective Critic Prompts:
The critic prompt is critical for pattern success. A vague critic request produces a vague feedback.
# Bad example: Vague critic prompt
WEAK_CRITIC_PROMPT = "Review this code and provide feedback."
# Good example: Structured critic prompt with specific criteria
STRONG_CRITIC_PROMPT = """
Review this Python code against these specific criteria:
1. CORRECTNESS (Critical)
- Does it handle the stated requirements?
- Are there logic errors or bugs?
- Are edge cases handled (empty input, None, large values)?
2. CODE QUALITY (Major)
- Follows PEP 8 style guidelines?
- Meaningful variable/function names?
- Appropriate use of Python idioms?
3. ERROR HANDLING (Major)
- Are exceptions caught and handled appropriately?
- Are error messages informative?
- Does it fail gracefully?
4. DOCUMENTATION (Minor)
- Are functions documented with docstrings?
- Are complex sections commented?
For each criterion, provide:
- Rating: PASS / NEEDS_IMPROVEMENT / FAIL
- Specific issues found (with line references if applicable)
- Concrete suggestions for improvement
Code to review:
```python
{code}
```
"""
Cross-Model Reflection:
Using the same model for creator and critic often creates an “echo chamber” where the critic approves flawed output because it has similar blind spots.
# Recommended approach: Cross-model reflection
creator = ModelFactory.create("gpt-4o") # Strong at generation
critic = ModelFactory.create("claude-sonnet-4-5") # Strong at analysis
# Alternative: Same provider, different temperatures
creator = ModelFactory.create("gpt-4o", temperature=0.7) # Creative
critic = ModelFactory.create("gpt-4o", temperature=0.2) # Analytical
When NOT to Use Reflection Pattern:
- Task has objective correctness criteria (you should use automated tests instead)
- Single-pass output is consistently acceptable
- Latency constraints don’t allow multiple iterations
- Cost per iteration is prohibitive for the use case
5. Tool Use – Extending Agent Capabilities
The Pattern: Tool Use pattern enables agents to interact with external APIs, databases or services by equipping agents with domain-specific tools that they can call on as needed by the task they received.
How It Works: The pattern is often implemented through a Function Calling mechanism which involves defining and describing external functions or capabilities to the LLM. In LangChain that is done using the @tool decorator:
from langchain_core.tools import tool
@tool
def tech_search(query: str) -> str:
"""Search for technology information."""
return search_tech_database(query)
@tool
def science_search(query: str) -> str:
"""Search for science information."""
return search_science_database(query)
llm_with_tools = llm.bind_tools([tech_search, science_search])
The LLM receives both the user’s request and available tool definitions. Based on this information, the LLM decides if calling one or more tools is required to generate response.
Sample Use Case: Research assistant:
- Query: “What is quantum computing?”
- Agent: Calls
tech_search("quantum computing") - Agent: Formulates answer using search results returned by the tool
Why It Matters: LLM model alone is limited to training data which may not had relevant information or had out of date data. The Tool Use pattern enables it to access additional information or real-time data and perform actions or calculations as needed for generating response.
Tool Description Best Practices:
The LLM model decides which tool to call based on the function name and description. Poor or incomplete descriptions often lead to incorrect tool selection.
# Bad choice: Vague description
@tool
def search(q: str) -> str:
"""Search for information."""
return search_database(q)
# Good choice: Specific description with usage guidance
@tool
def search_tech_patents(query: str, year_from: int = 2020) -> str:
"""Search USPTO patent database for technology-related patents.
Use this tool when the user asks about:
- Patents, inventions, or intellectual property
- Technology innovations and their inventors
- Prior art research
Args:
query: Search terms (e.g., "machine learning image recognition")
year_from: Filter patents from this year onward (default: 2020)
Returns:
JSON string with patent titles, numbers, abstracts, and filing dates.
Returns empty array if no matches found.
"""
return search_patent_db(query, year_from)
Tool Execution Patterns:
Tools can be used in various patterns depending on the task:
| Pattern | Description | Example |
|---|---|---|
| Single tool | One tool call, use result | “What’s the weather?” -> call weather_api() |
| Sequential | Output of A feeds into B | search -> summarize results |
| Parallel | Multiple tools simultaneously | weather + news + calendar |
| Iterative | Same tool, refined queries | search -> refine -> search again |
Sequential Tool Chain:
@tool
def web_search(query: str) -> str:
"""Search the web for current information."""
return search_api(query)
@tool
def summarize_results(search_results: str) -> str:
"""Summarize search results into key points."""
return llm.invoke(f"Summarize: {search_results}")
# Agent decides to chain: search → summarize
Error Handling for Tools:
Tools can fail. You should design agents to handle failures gracefully:
@tool
def reliable_search(query: str) -> str:
"""Search with automatic retry and fallback."""
# Attempt primary source
try:
result = primary_search_api(query, timeout=5)
if result:
return result
except TimeoutError:
pass # Fall through to backup
except APIError as e:
logger.warning(f"Primary search failed: {e}")
# Attempt backup source
try:
result = backup_search_api(query, timeout=10)
if result:
return f"[From backup source] {result}"
except Exception as e:
logger.error(f"Backup search failed: {e}")
# Graceful degradation
return "Search unavailable. Please try rephrasing your query or try again later."
Tool Selection Prompt Enhancement:
Always consider how to help the LLM model to make better tool selection decision:
TOOL_SELECTION_SYSTEM_PROMPT = """
You have access to these tools:
{tool_descriptions}
Guidelines for tool selection:
1. Only use tools when the information is not in your training data
2. For current events, prices, or real-time data: ALWAYS use tools
3. If multiple tools could work, prefer the most specific one
4. If a tool fails, try rephrasing the query before giving up
5. Explain your tool choice briefly before calling it
When NOT to Use Tool Use Pattern:
- Information is certainly available in the LLM’s training data
- Tool latency would result in unacceptably slow responses
- Task can be completed with LLM reasoning alone
- Tool results would need extensive validation
Orchestration Patterns (6-7) – Complex Workflows
Intelligent behavior often requires an agent to break down a complex task into smaller steps that are planned to achieve the task goal once all the steps are completed. Some steps may require domain expertise or use of specific tools therefore, the plan should account for collaboration with specialized agents that have required expertise or tools. Design patterns in this group offer a standardized solution for having agentic system first to create a coherent plan to meet a goal and then coordinating multiple agent to execute this plan.
6. Planning – Strategic Breakdown and Execution
The Pattern: Planning pattern involves breaking a complex task into smaller steps, creating an execution plan and then following it step-by-step to achieve the final goal.
How It Works: Two-phase approach using LangGraph state machine:
from langgraph.graph import StateGraph, END
workflow = StateGraph(PlanningState)
workflow.add_node("planner", planner_agent) # Phase 1: Create plan
workflow.add_node("executor", executor_agent) # Phase 2: Execute plan
workflow.add_edge("planner", "executor")
Sample Use Case: Design RESTful API for a book library system
- Planner: Analyzes requirements, breaks into steps (entities, relationships, constraints)
- Executor: Create design for each step, produces SQL schema
Why It Matters: Handling complex tasks benefit from decomposing high-level requirements into actionable, sequential steps and creating an explicit plan with detailed design for each step before execution.
Plan Representation Formats:
You need to decide what structure to use for creating plans as that may affect plan execution quality, for example:
1. Linear Plans – a sequential list of items
2. Directed Acyclic Graph (DAG) Plans – a non-linear list of items with dependencies
3. Hierarchical Plans – nested goals:
Goal: Design Library API
├── SubGoal 1: Define Data Model
│ ├── Task 1.1: Identify core entities
│ ├── Task 1.2: Define entity attributes
│ └── Task 1.3: Map relationships
├── SubGoal 2: Design API Endpoints
│ ├── Task 2.1: CRUD operations
│ ├── Task 2.2: Search functionality
│ └── Task 2.3: Authentication endpoints
└── SubGoal 3: Define Validation Rules
├── Task 3.1: Input validation
└── Task 3.2: Business rules
Structured Plan Generation:
PLANNING_PROMPT = """
Create an execution plan for this task. Return a structured plan with:
1. GOAL: One sentence describing the end state
2. STEPS: Numbered list where each step has:
- Description: What to do
- Inputs: What information is needed
- Outputs: What this step produces
- Dependencies: Which steps must complete first (use step numbers)
Task: {task}
Example format:
GOAL: Create a REST API design for a library system
STEPS:
1. Description: Identify core entities
Inputs: Requirements document
Outputs: Entity list with attributes
Dependencies: None
2. Description: Define relationships
Inputs: Entity list
Outputs: ER diagram description
Dependencies: Step 1
"""
Plan Validation:
Before passing the plan to an agent for execution, you should validate it, for example:
def validate_plan(plan: dict) -> tuple[bool, list[str]]:
"""Validate plan structure and dependencies."""
errors = []
# Check for circular dependencies
if has_circular_deps(plan["steps"]):
errors.append("Circular dependency detected")
# Check all dependencies exist
step_ids = {s["id"] for s in plan["steps"]}
for step in plan["steps"]:
for dep in step.get("dependencies", []):
if dep not in step_ids:
errors.append(f"Step {step['id']} depends on non-existent step {dep}")
# Check inputs are available
available_outputs = set()
for step in topological_sort(plan["steps"]):
for required_input in step.get("inputs", []):
if required_input not in available_outputs and required_input != "initial":
errors.append(f"Step {step['id']} requires unavailable input: {required_input}")
available_outputs.update(step.get("outputs", []))
return len(errors) == 0, errors
Adaptive Re-planning:
In real-life, task execution can often deviates from the generated plan. It is recommended to build in re-planning capability to account for changes in task execution, for example:
async def execute_with_replanning(plan: dict, max_replans: int = 2):
replan_count = 0
for step in plan["steps"]:
try:
result = await execute_step(step)
step["result"] = result
except ExecutionError as e:
if replan_count >= max_replans:
raise RuntimeError(f"Max replanning attempts exceeded at step {step['id']}")
# Generate new plan from current state
new_plan = await planner.invoke({
"original_goal": plan["goal"],
"completed_steps": [s for s in plan["steps"] if "result" in s],
"failed_step": step,
"error": str(e)
})
plan = new_plan
replan_count += 1
return plan
When NOT to Use Planning Pattern:
- Task is straightforward enough for direct execution
- Planning overhead exceeds execution time
- Requirements are too vague for meaningful decomposition
- Real-time response is required
7. Multi-Agent Collaboration – Coordinated Teamwork
The Pattern: Multi-Agent Collaboration pattern involves creating a system of multiple specialized agents that work together in a structured way through defined communication protocols and interaction models allowing the group to deliver solution that would be impossible for any single agent.
Sample Use Cases:
To illustrate use of the Multi-Agent Collaboration pattern, I used LangGraph to demonstrate three different collaboration models:
- Sequential Pipeline: Research paper analysis (Researcher -> Critic -> Synthesizer)
- Parallel & Synthesis: Product launch campaign (Marketing + Content + Analyst -> Coordinator)
- Multi-Perspective Debate: Code review system (Security + Performance + Quality -> Synthesizer)
Sequential Pipeline: Research -> Critic -> Synthesizer:
workflow.add_edge("researcher", "critic")
workflow.add_edge("critic", "summarizer")
Parallel & Synthesis: Marketing + Content + Analyst -> Coordinator:
workflow.add_edge("marketing", "coordinator")
workflow.add_edge("content", "coordinator")
workflow.add_edge("analyst", "coordinator")
Multi-Perspective Debate: Security + Performance + Quality -> Synthesizer:
workflow.add_edge("security_reviewer", "synthesizer")
workflow.add_edge("performance_reviewer", "synthesizer")
workflow.add_edge("quality_reviewer", "synthesizer")
Why It Matters: Problems that agents face in real-life often require involvement of specialized agents working together in different collaboration structures. LangGraph library makes it easy to implement any collaboration pattern.
State Management in Multi-Agent Systems:
LangGraph uses a shared state object that all agents read from and write to:
from typing import TypedDict, List, Annotated
from langgraph.graph import StateGraph
from langchain_core.messages import BaseMessage
import operator
class CollaborationState(TypedDict):
# Original input
task: str
# Agent outputs (each agent writes to their field)
research_output: str
critique: str
final_summary: str
# Shared conversation history (appended by all agents)
messages: Annotated[List[BaseMessage], operator.add]
# Metadata for coordination
iteration: int
status: str # "in_progress", "needs_revision", "complete"
Agent Role Definition Best Practices:
You should define strong agent role boundaries to prevent agents from either duplicating work, or providing generic feedback, for example:
SECURITY_REVIEWER_PROMPT = """
You are a senior security engineer reviewing code.
YOUR SCOPE - Focus ONLY on:
1. Authentication and authorization vulnerabilities
2. Input validation and injection risks (SQL, XSS, command injection)
3. Sensitive data exposure (logging, error messages, hardcoded secrets)
4. Dependency vulnerabilities (known CVEs)
5. Cryptographic issues (weak algorithms, improper key handling)
OUT OF SCOPE - DO NOT comment on:
- Code style or formatting
- Performance optimizations
- Documentation quality
- General code structure
OUTPUT FORMAT:
For each issue found:
- Severity: CRITICAL / HIGH / MEDIUM / LOW
- Location: File and line number
- Issue: Brief description
- Recommendation: Specific fix
If no security issues found, respond with: "No security vulnerabilities identified."
"""
PERFORMANCE_REVIEWER_PROMPT = """
You are a performance engineer reviewing code.
YOUR SCOPE - Focus ONLY on:
1. Algorithm complexity (O(n²) when O(n) is possible)
2. Database query efficiency (N+1 queries, missing indexes)
3. Memory usage (large object creation, memory leaks)
4. Caching opportunities
5. Async/concurrent execution opportunities
OUT OF SCOPE - DO NOT comment on:
- Security vulnerabilities
- Code style
- Documentation
OUTPUT FORMAT:
For each issue found:
- Impact: HIGH / MEDIUM / LOW
- Location: File and function
- Current: What the code does now
- Suggested: Specific optimization
- Expected improvement: Estimated gain
"""
Coordination Challenges and Solutions:
| Challenge | Example | Solution |
|---|---|---|
| Conflicting outputs | Security: “add auth” vs Performance: “reduce overhead” | Synthesizer with explicit conflict resolution rules |
| Information loss | Key details lost between agents | Structured hand-off format with required fields |
| Infinite loops | Agents keep requesting revisions | Max iteration limits, improvement thresholds |
| Redundant work | Multiple agents analyze same aspect | Clear scope boundaries, explicit “out of scope” |
Conflict Resolution in Synthesizer:
SYNTHESIZER_PROMPT = """
You are a technical lead synthesizing feedback from multiple reviewers.
Reviews received:
- Security Review: {security_review}
- Performance Review: {performance_review}
- Quality Review: {quality_review}
Your task:
1. Identify CONFLICTS where reviewers disagree or recommendations are mutually exclusive
2. For each conflict, decide the resolution based on these priorities:
- Security concerns ALWAYS take precedence
- Correctness over performance
- Maintainability over micro-optimizations
3. Create a UNIFIED action plan that:
- Lists all non-conflicting recommendations
- Explains conflict resolutions with rationale
- Prioritizes items as: MUST DO / SHOULD DO / NICE TO HAVE
Output a single, coherent improvement plan the developer can follow.
"""
Structured Hand-off Between Agents:
HANDOFF_TEMPLATE = """
## Agent Handoff Document
### Completed By: {previous_agent}
### Handing To: {next_agent}
### Summary of Work Done:
{work_summary}
### Key Findings:
{key_findings}
### Open Questions:
{open_questions}
### Recommendations for Next Agent:
{recommendations}
### Artifacts Produced:
{artifacts}
"""
When NOT to Use Multi-Agent Collaboration Pattern:
- Single perspective on task execution is sufficient
- Multi-agent coordination overhead exceeds benefits
- Agents would have highly overlapping responsibilities
- Task requires sharing deep context that’s hard to transfer between agents
Advanced Patterns (8-10) – Self-Improvement & Quality Assurance
Agentic systems need to remember information from past interactions not only to provide coherent and personalized user experience, but also to learn and self-improve using collected data. Design patterns in this group enable agents to remember past conversations, learn from them, and improve over time.
8. Memory Management – Context Across Interactions
The Pattern: Memory Management pattern is very important as it allows agents to keep track of conversations, personalize responses, or learn from the interactions. LLM models rely on three memory types:
- Semantic Memory: Facts and knowledge (user preferences, domain knowledge)
- Episodic Memory: Past experiences (conversation history, previous tickets)
- Procedural Memory: Rules and strategies (company policies, protocols)
How It Works: LangChain offers ConversationBuifferMemory to automatically inject the history of a single conversation into a prompt, LangGraph enables advanced, long-term memory via the InMemoryStore:
from langgraph.store.memory import InMemoryStore
memory = InMemoryStore()
# Store semantic knowledge
await memory.aput(
namespace=("advisor", "semantic"),
key="tax_401k",
value={"concept": "401k", "info": "Tax-advantaged retirement..."}
)
# Retrieve when needed
knowledge = await memory.aget(("advisor", "semantic"), "tax_401k")
Sample Use Case: Financial advisor chat bot:
- Remembers user’s investment preferences (semantic memory)
- Recalls past conversations (episodic memory)
- Follows fiduciary duty rules (procedural memory)
Why It Matters: Without a memory mechanism, agents are stateless. They are unable to maintain conversational context, learn from experience, or personalize responses for users.
Agent Memory Architecture Decisions:
Your choice of storage backend for agentic application is always based on use case requirements:
| Backend | Persistence | Scalability | Query Types | Best For |
|---|---|---|---|---|
| InMemoryStore | Session only | Single instance | Key-value | Prototyping, demos |
| Redis | Configurable | High (clustered) | Key-value, TTL | Production, multi-instance |
| PostgreSQL + pgvector | Yes | High | SQL + semantic | Complex queries + similarity |
| Pinecone/Weaviate | Yes | Very high | Semantic only | Large-scale retrieval |
| SQLite | Yes | Low | SQL | Desktop apps, edge comp. |
Memory Retrieval Strategies:
Keep in mind that how you retrieve memories can affect response quality, for example:
# Strategy 1: Recency-based (last N interactions)
async def get_recent_memories(user_id: str, n: int = 5):
memories = await memory.alist(namespace=("user", user_id, "episodic"))
return sorted(memories, key=lambda m: m["timestamp"], reverse=True)[:n]
# Strategy 2: Relevance-based (semantic similarity)
async def get_relevant_memories(user_id: str, query: str, n: int = 5):
query_embedding = embed_model.embed(query)
memories = await memory.asearch(
namespace=("user", user_id, "episodic"),
query_embedding=query_embedding,
top_k=n
)
return memories
# Strategy 3: Hybrid (recent + relevant)
async def get_hybrid_memories(user_id: str, query: str):
recent = await get_recent_memories(user_id, n=3)
relevant = await get_relevant_memories(user_id, query, n=3)
# Deduplicate and merge
seen_ids = set()
combined = []
for mem in recent + relevant:
if mem["id"] not in seen_ids:
combined.append(mem)
seen_ids.add(mem["id"])
return combined
Memory Types Implementation:
class FinancialAdvisorMemory:
def __init__(self, store: InMemoryStore, user_id: str):
self.store = store
self.user_id = user_id
# SEMANTIC: Facts and knowledge
async def store_user_preference(self, key: str, value: dict):
await self.store.aput(
namespace=("advisor", self.user_id, "semantic"),
key=key,
value={"type": "preference", "data": value, "updated": datetime.now().isoformat()}
)
# EPISODIC: Past interactions
async def log_interaction(self, interaction: dict):
interaction_id = f"interaction_{datetime.now().timestamp()}"
await self.store.aput(
namespace=("advisor", self.user_id, "episodic"),
key=interaction_id,
value={"type": "interaction", "data": interaction, "timestamp": datetime.now().isoformat()}
)
# PROCEDURAL: Rules and strategies
async def get_compliance_rules(self) -> list:
rules = await self.store.aget(
namespace=("advisor", "global", "procedural"),
key="compliance_rules"
)
return rules["data"] if rules else []
Memory Consolidation:
Volume of episodic memories can significantly grow aver time. Therefor, detailed episodic memories should be periodically compressed into summarized semantic knowledge to manage the size / limit of the context window, for example:
async def consolidate_memories(user_id: str, days_old: int = 30):
"""Compress old episodic memories into semantic summaries."""
cutoff = datetime.now() - timedelta(days=days_old)
old_memories = await get_memories_before(user_id, cutoff)
if not old_memories:
return
# Group by topic
grouped = group_by_topic(old_memories)
for topic, memories in grouped.items():
# Generate summary
summary = llm.invoke(f"""
Summarize these past interactions about {topic}:
{format_memories(memories)}
Extract:
1. Key facts learned about the user
2. Preferences expressed
3. Important decisions made
""")
# Store as semantic memory
await memory.aput(
namespace=("user", user_id, "semantic"),
key=f"consolidated_{topic}",
value={"summary": summary, "source_count": len(memories), "consolidated_at": datetime.now().isoformat()}
)
# Archive or delete old episodic memories
for mem in memories:
await memory.adelete(namespace=("user", user_id, "episodic"), key=mem["id"])
When NOT to Use Memory Management Pattern:
- Stateless interactions are acceptable in your use case (e.g., simple Q&A chat)
- Privacy requirements prohibit storing user data
- Context window size is sufficient for conversation history for your use case
- Memory maintenance complexity exceeds benefits
9. Learning & Adapting – Self-Improvement Through Benchmarking
The Pattern: Learning & Adapting pattern enable agents to iteratively evolve by autonomously improving its parameters or even, its own code based on test results. Without this ability their performance can degrade when faced with a novel task.
How It Works: Agent follows Benchmark -> Analyze -> Improve itslef cycle:
for iteration in range(max_iterations):
# Run benchmark tests
test_results = benchmark.run(current_code)
# Calculate performance score (success rate, speed, complexity)
score = calculate_score(test_results)
# If good enough, stop
if score >= threshold:
break
# Use LLM to generate improved version
improved_code = llm.invoke(f"""
Current code: {current_code}
Test failures: {test_results.failures}
Generate improved version.
""")
current_code = improved_code
Sample Use Case: An agent that improves its own code through cycles of:
- Testing current implementation
- Analyzing performance and failures
- Generating improved version
- Selecting best version for next iteration
Scoring Formula: Best version is selected using weighted combination of three factors:
foodescore = 0.5 × success_rate + 0.3 × speed + 0.2 × simplicity
Why It Matters: Demonstrates meta-learning – an agent that autonomously improves its behavior based on new data and iterations. Pattern is applicable to prompt engineering, hyper-parameter tuning, and automated optimization.
Designing Effective Benchmarks:
Remember that quality of your benchmark determines agent learning quality. Therefore, a comprehensive benchmark suite should include different test types:
| Test Type | Purpose | Example |
|---|---|---|
| Correctness | Does output match expected? | sort([3,1,2]) -> [1,2,3] |
| Edge cases | Handles boundaries? | Empty list, single element, duplicates, etc. |
| Performance | Meets speed requirements? | Sort 10,000 elements in < 100ms |
| Robustness | Handles bad input? | None, wrong types, malformed data |
| Scale | Works at production volume? | 1M element sort |
Comprehensive Benchmark Example:
SORTING_BENCHMARK = [
# Correctness tests
{"name": "basic_sort", "input": [3, 1, 4, 1, 5], "expected": [1, 1, 3, 4, 5]},
{"name": "already_sorted", "input": [1, 2, 3, 4, 5], "expected": [1, 2, 3, 4, 5]},
{"name": "reverse_sorted", "input": [5, 4, 3, 2, 1], "expected": [1, 2, 3, 4, 5]},
# Edge cases
{"name": "empty_list", "input": [], "expected": []},
{"name": "single_element", "input": [42], "expected": [42]},
{"name": "all_same", "input": [7, 7, 7, 7], "expected": [7, 7, 7, 7]},
{"name": "negative_numbers", "input": [-3, -1, -4], "expected": [-4, -3, -1]},
{"name": "mixed_signs", "input": [-2, 0, 3, -1], "expected": [-2, -1, 0, 3]},
# Performance tests (check timing separately)
{"name": "large_random", "input": list(range(10000, 0, -1)), "expected": list(range(1, 10001)), "max_ms": 100},
{"name": "large_uniform", "input": [1] * 10000, "expected": [1] * 10000, "max_ms": 50},
]
def run_benchmark(code: str, benchmark: list) -> dict:
"""Execute code against benchmark suite."""
results = {
"passed": 0,
"failed": 0,
"errors": 0,
"failures": [],
"total_time_ms": 0
}
exec_globals = {}
exec(code, exec_globals)
sort_func = exec_globals.get("sort") or exec_globals.get("custom_sort")
for test in benchmark:
try:
start = time.perf_counter()
result = sort_func(test["input"].copy())
elapsed_ms = (time.perf_counter() - start) * 1000
results["total_time_ms"] += elapsed_ms
if result != test["expected"]:
results["failed"] += 1
results["failures"].append({
"test": test["name"],
"expected": test["expected"][:5], # Truncate for logging
"got": result[:5] if result else None
})
elif "max_ms" in test and elapsed_ms > test["max_ms"]:
results["failed"] += 1
results["failures"].append({
"test": test["name"],
"reason": f"Too slow: {elapsed_ms:.1f}ms > {test['max_ms']}ms"
})
else:
results["passed"] += 1
except Exception as e:
results["errors"] += 1
results["failures"].append({
"test": test["name"],
"error": str(e)
})
return results
Avoiding Local Optima:
Keep in mind that agent learning loop can get stuck optimizing for specific failing tests while regressing on others. Therefore, you should always track the overall agent performance, for example:
def adaptive_learning_loop(initial_code: str, benchmark: list, max_iterations: int = 10):
current_code = initial_code
best_code = initial_code
best_score = 0.0
# Track performance across ALL tests, not just failing ones
history = []
for i in range(max_iterations):
# Randomize test order to prevent order-dependent optimizations
shuffled_benchmark = random.sample(benchmark, len(benchmark))
results = run_benchmark(current_code, shuffled_benchmark)
score = calculate_score(results)
history.append({"iteration": i, "score": score, "passed": results["passed"]})
# Track best overall, not just most recent
if score > best_score:
best_score = score
best_code = current_code
if results["failed"] == 0 and results["errors"] == 0:
return best_code, history, "All tests passed"
# Periodically reintroduce tests that were passing
# to catch regressions
if i > 0 and i % 3 == 0:
regression_check = run_benchmark(current_code, benchmark)
if regression_check["passed"] < history[0]["passed"]:
# Regression detected, revert to best
current_code = best_code
continue
# Generate improvement focused on failures
current_code = llm.invoke(f"""
Current code:
```python
{current_code}
```
Test failures:
{json.dumps(results["failures"], indent=2)}
Previous attempts: {len(history)}
Best score achieved: {best_score:.2f}
Generate an improved version that:
1. Fixes the failing tests
2. Does NOT break currently passing tests
3. Maintains or improves performance
""")
return best_code, history, f"Max iterations reached (best score: {best_score:.2f})"
Scoring Formula Variations:
Different tasks typically need different scoring weights, for example:
# Correctness-focused (typical for most cases)
score = 0.7 * success_rate + 0.2 * (1 - normalized_time) + 0.1 * simplicity
# Performance-critical (real-time systems)
score = 0.4 * success_rate + 0.5 * (1 - normalized_time) + 0.1 * simplicity
# Maintainability-focused (enterprise code)
score = 0.5 * success_rate + 0.1 * (1 - normalized_time) + 0.4 * simplicity
When NOT to Use Learning & Adapting Pattern:
- Task doesn’t have measurable success criteria
- Cost of benchmark testst creation exceeds expected benefits
- Solution space is too large for iterative search to succeede quickly
- Human review is required anyway
10. Goal Setting & Monitoring – Quality Assurance Through Review Cycles
The Pattern: Goal Setting & Monitoring patterns is about setting a specific goal for an agent and providing the means to track the progress and determine if goal is achieved.
How It Works: Pattern is demonstrated using two agents:
- Developer Agent:
- Analyzes requirements
- Creates implementation plan
- Writes Python code
- Revises code based on feedback
- Manager Agent:
- Reviews code against requirements
- Grades the code across 4 criteria (0-100 scale):
- Requirements coverage (40%)
- Code quality (30%)
- Error handling (15%)
- Code documentation (15%)
- Provides prioritized, actionable feedback
Agents collaborate via the following iteration cycle:
- Developer agent that creates implementation plans and generates code
- Manager agent that monitors progress, reviews code, and provides feedback
- Iterative improvement cycle based on manager feedback
- Grade-based progress tracking – iterations will stop if grade is above 85
Sample Use Case: REST API client implementation based on simple requirements: retry logic, rate limiting, error handling
Why It Matters: The pattern provides a standardize solution by giving LLM model a sense of purpose and self-assessment. Automated code review and quality assurance use case shows how multi-agent collaboration enables complex quality control workflows.
Designing Effective Grading Rubrics:
You should alwaws rememebr that vague prompt, such as vague rubrics will lead to inconsistent grading. Therefore, be explicit in the prompt about what each score means:
GRADING_RUBRIC = {
"requirements_coverage": {
"weight": 0.40,
"criteria": {
"90-100": "All requirements fully implemented with edge cases handled",
"80-89": "All core requirements implemented, minor edge cases missing",
"70-79": "Most requirements implemented, some gaps in functionality",
"60-69": "Partial implementation, missing key requirements",
"0-59": "Fundamental requirements not addressed"
}
},
"code_quality": {
"weight": 0.30,
"criteria": {
"90-100": "Clean, idiomatic Python following PEP 8, well-structured with appropriate abstractions",
"80-89": "Readable and maintainable, minor style inconsistencies",
"70-79": "Functional but could be cleaner, some code smells",
"60-69": "Works but hard to maintain, significant style issues",
"0-59": "Poorly structured, major code smells, difficult to understand"
}
},
"error_handling": {
"weight": 0.15,
"criteria": {
"90-100": "Comprehensive error handling with specific exceptions, informative messages, graceful degradation",
"80-89": "Good error handling for common cases, reasonable messages",
"70-79": "Basic error handling present, generic exceptions",
"60-69": "Minimal error handling, may crash on bad input",
"0-59": "No error handling, crashes easily"
}
},
"documentation": {
"weight": 0.15,
"criteria": {
"90-100": "Complete docstrings, clear comments for complex logic, usage examples",
"80-89": "Good docstrings for public functions, adequate comments",
"70-79": "Basic documentation present, some gaps",
"60-69": "Minimal documentation, unclear function purposes",
"0-59": "No documentation"
}
}
}
Manager Prompt with Explicit Rubric:
MANAGER_REVIEW_PROMPT = """
You are a senior engineering manager reviewing code against specific requirements.
## Requirements:
{requirements}
## Code to Review:
```python
{code}
```
## Grading Rubric:
{rubric}
## Your Task:
1. Grade each criterion using the rubric descriptions
2. Calculate weighted total: (req × 0.40) + (quality × 0.30) + (errors × 0.15) + (docs × 0.15)
3. Provide feedback in two categories:
### PRIORITY FEEDBACK (Must fix before passing):
- Critical bugs or missing requirements
- Security vulnerabilities
- Major functionality gaps
### SECONDARY IMPROVEMENTS (Nice to have):
- Code style refinements
- Documentation enhancements
- Performance optimizations
## Output Format:
REQUIREMENTS_COVERAGE: [score]/100
Justification: [one line]
CODE_QUALITY: [score]/100
Justification: [one line]
ERROR_HANDLING: [score]/100
Justification: [one line]
DOCUMENTATION: [score]/100
Justification: [one line]
TOTAL: [weighted score]/100
PRIORITY FEEDBACK:
1. [issue]
2. [issue]
SECONDARY IMPROVEMENTS:
1. [suggestion]
2. [suggestion]
"""
When NOT to Use Goal Setting & Monitoring Pattern:
- Task doesn’t have clear success criteria
- Single-pass generation is sufficient to generate response
- Human review of response is required regardless
- Iteration cost (API calls, time) exceeds benefits
11. Retrieval-Augmented Generation (RAG) – Access Context Specific Data
The Pattern: RAG pattern enables LLM to access and integrate external, current, and context-specific information to enhance the accuracy, relevance and factual basis of LLM response.
How It Works:
- User request is analyzed to determine question type (factual, comparison, overview, etc.)
- Based on the question type, system determines what information is required to answer it
- Simple RAG process involves Retrieval (searching a knowledge base for relevant content) and Augmentation (adding citations from retrieved documents to the LLM prompt)
- GraphRAG process also leverages connections between different entities (nodes in the knowledge graph) which allows system to answer questions that require knowledge of relationships between different pieces of information / documents.
Why It Matters:
- Grounds responses in facts: Allows reducing hallucinations by providing source material
- Enables domain-specific knowledge: Provides access to proprietary documents, databases, or specialized corporate information
- Dynamic knowledge: Enables updating knowledge base used by LLM without retraining the model
- Transparency: Can cite sources for information used to generate answers
Sample Use Cases:
- Question answering over enterprise documents
- Customer support with knowledge base integration
- Research assistants with access to a library of scientific papers
- Legal or medical applications requiring factual accuracy of generated answers
Note: While RAG is a very important agentic design pattern, it’s not implemented in the testing framework. I’ve have a separate GraphRAG project that uses this design paternal to build an application that demonstrates advanced retrieval techniques including graph-based knowledge representation, multi-hop reasoning, and hybrid search strategies. You can find more information about this project in the blogs:
- Building a GraphRAG System – Core Infrastructure & Document Ingestion
- GraphRAG Part 2 – Cross-Doc & Sub-graph Extraction, Multi-Vector Entity Representation
- GraphRAG Part 3 – Intelligent MVR, Query Routing and Context Generation
- GraphRAG Part 4 – Community Detection and Embedding, Search and Hybrid Retrieval Integration
Why Separate?: GraphRAG requires significant infrastructure (object storage for documents, graph database, vector databases, embedding models, indexing pipelines) that deserves a dedicated attention. The GraphRAG project explores these components in depth.
Combining Patterns: Real-World Applications
Individual patterns are building blocks for agentic applications. In real-world production application, you would typically need to combine multiple patterns:
Example: AI Code Assistant
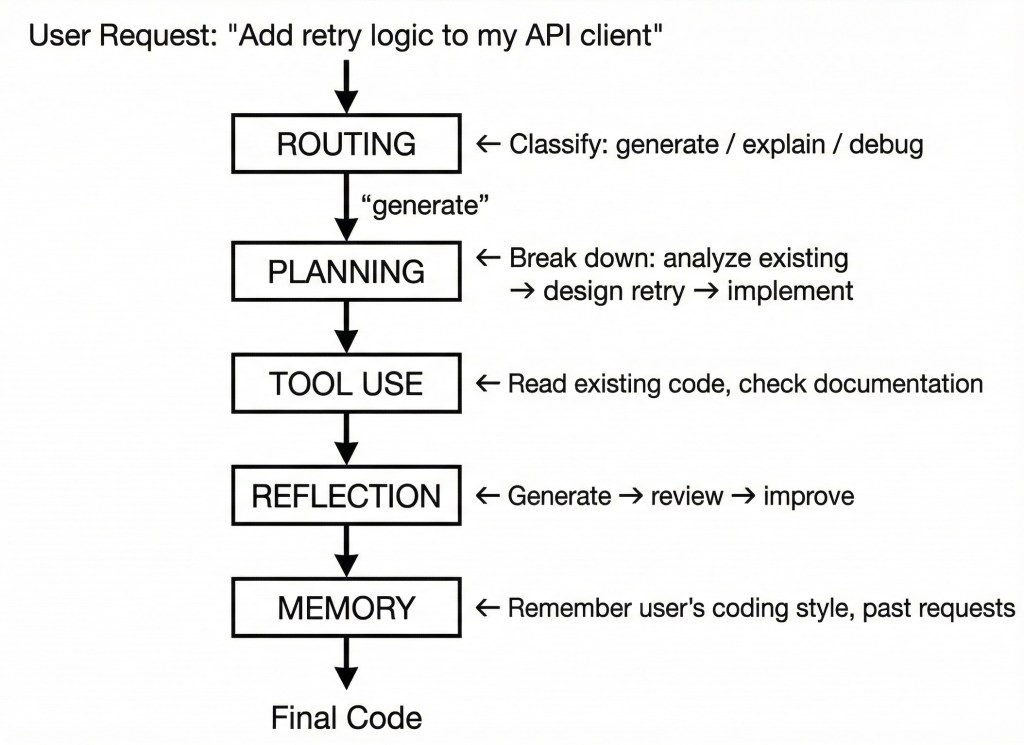
Example: Research Analyst Agent
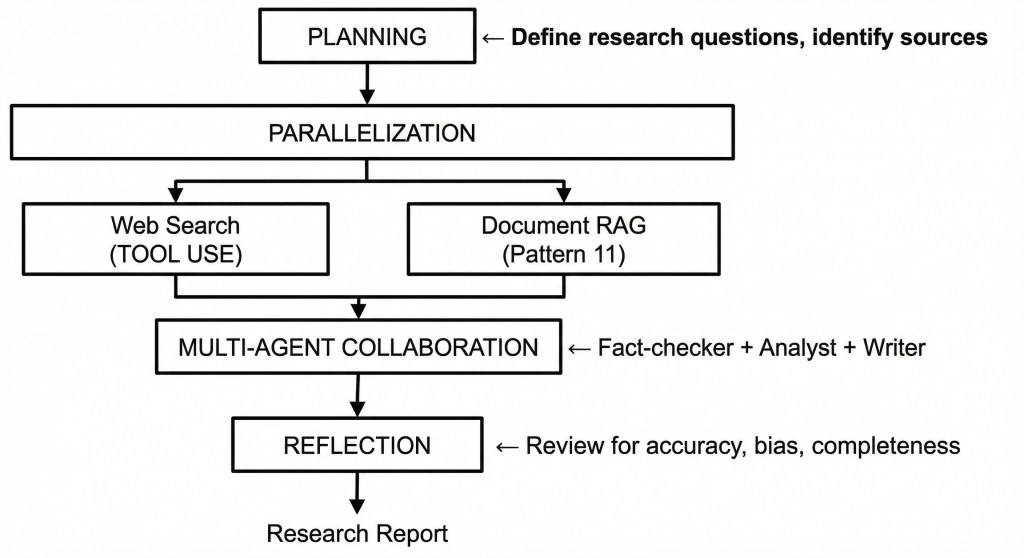
Pattern Combination Guidelines:
| Combination | When to Use | Watch Out For |
|---|---|---|
| Routing + Specialized Chains | Multiple distinct request types | Misclassification cascades |
| Planning + Multi-Agent | Complex tasks needing expertise | Coordination overhead |
| Tool Use + Reflection | External data needs verification | Tool failures during reflection |
| Memory + Any Pattern | Personalization needed | Memory retrieval latency |
| Parallelization + Synthesis | Independent analyses to combine | Context window limits |
Anti-Pattern: Over-Engineering
Not every agentic application needs using every design pattern. A simple FAQ chatbot using Routing and Tool Use patterns (for knowledge base search) likely will be more effective than a complex multi-agent system.
Rule of thumb: Start with the simplest pattern that could work.
Add complexity only when you have evidence it’s needed.
Key Insights and Comparison Results
Cost and Latency Implications
Understanding the resource implications of each pattern helps in architecture decisions:
| Pattern | API Calls per Request | Relative Cost | Latency Impact |
|---|---|---|---|
| Chaining | N (number of steps) | Medium | Additive (+N calls) |
| Routing | 1 (classify) + handler | Low-Medium | +1 classification call |
| Parallelization | N (parallel tasks) | Medium-High | Reduced (concurrent) |
| Reflection | 2-6 (iterations × 2) | High | 2× per iteration |
| Tool Use | 1 + tool calls | Low-Medium | +tool latency |
| Planning | 2+ (plan + execute) | Medium | +planning phase |
| Multi-Agent | 3-10+ (varies) | Highest | Depends on topology |
| Memory | 1 + retrieval | Low-Medium | +retrieval latency |
| Learning & Adapting | 5-20+ (iterations) | Very High | Minutes to hours |
| Goal Monitoring | 4-14 (iterations × 2) | High | Minutes |
Cost Optimization Strategies
1. Model Tiering: Use cheaper LLM models for simpler tasks:
# Expensive model for final output only
classifier = ModelFactory.create("gpt-4o-mini") # Cheap, fast
generator = ModelFactory.create("gpt-4o") # Expensive, high quality
2. Early Termination: Stop iterations when good enough:
if quality_score >= 0.85:
break # Don't over-optimize
3. Caching: Store and reuse common results:
@lru_cache(maxsize=1000)
def classify_intent(request_hash: str) -> str:
return classifier.invoke(request)
4. Batching: Combine multiple small requests:
# Instead of 10 separate calls
results = await asyncio.gather(*[process(item) for item in items])
### Latency Budget Example:
For a 3-second response time budget:
| Component | Budget | Design Pattern Choice |
|---|---|---|
| Classification | 300ms | Keyword matching (no LLM) | |
| Main processing | 2000ms | Single LLM call or 2-step chain |
| Tool calls | 500ms | Max 1-2 fast tools |
| Synthesis | 200ms | Lightweight post-processing |
For a 30-second budget which is ussually acceptable for complex tasks:
- Full planning phase
- 2-3 reflection iterations
- Multi-agent collaboration (sequential)
LLM Model Performance
After implementing these 10 patterns across multiple LLM providers I nmotices that Model Performance Varies by Pattern:
- Code generation (Reflection, Learning & Adapting): GPT-4o and Claude Sonnet excel
- Structured planning (Planning, Goal Monitoring): Claude Sonnet provides more detailed plans
- Tool use: GPT-4o has more reliable function calling
- Multi-step reasoning: All frontier models (GPT-4o, Claude Sonnet 4.5, Gemini 3.5 Pro) perform well
The Framework’s Value: Having a consistent testing harness made it possible to quickly prototype patterns, compare models objectively, and identify which combinations work best for specific tasks.
Conclusion and What’s Next
This project demonstrates that agentic design patterns are not just theoretical concepts. Like software design patterns, they’re practical solutions with measurable benefits. The testing framework implements 10 core patterns using LangChain and LangGraph, with the ability to run and compare them across OpenAI, Anthropic, and Google models.
Key Takeaways:
- Design Patterns matter: Structured workflows significantly outperform single LLM calls
- Different tasks need different patterns**: There is no one-size-fits-all solution
- Model choice matters: Different LLMs have different strengths
- Frameworks accelerate development: LangChain and LangGraph abstract model APIs and provide tools to dramatically speed up workflows development
In this project I focused on intra-application agent communication where agents collaborate within a single application runtime. But building an agentic system often involve inter-applicatio communication:
- Inter-Agent Communication (A2A): Google’s protocol for agents from different systems to discover, negotiate, and coordinate with each other
- Model Context Protocol (MCP): Anthropic’s protocol for agents to access tools and resources across application boundaries
- Hybrid architectures: Combining intra-application patterns (like those implemented here) with inter-application protocols
Part 2 will explore these communication paradigms, their trade-offs, and how they complement the design patterns covered in this post.
Framework code is open source shared in GitHub repository. Try running the patterns, compare models, and adapt them to your use cases. The future of AI applications is agentic – these patterns are your starting point.
