
How hippocampal-inspired memory consolidation and Personalized PageRank give AI assistants structured recall across conversations and documents.
Why We Built ENGRAM Personal Memory
ENGRAM’s memory management system (originally built for the Biomedical Research Assistant project) takes a hippocampal-inspired approach: working memories discovered in a current session are importance-scored and periodically consolidated into long-term memories that persist as Memory nodes in a knowledge graph. These Memory nodes connect to extracted conceptual entities (locations, technology terms, people, concepts) via weighted edges, enabling Personalized PageRank(PPR)-based recall of relevant context.
ENGRAM proved highly effective for memory recall in long-running conversations across multiple agents. That got me thinking: could it improve context recall in the long, document-heavy conversations typical of real-life AI assistant usage?
Current LLM memory systems store user context as flat text summaries — compressed natural language with no structure, no entity relationships, and no weighted relevance. This limits them to recency-based context selection and prevents cross-conversation coherence. A question about database migrations can’t automatically surface your earlier UI framework decision because there’s no structural connection between them.
There’s a challenge, though. ENGRAM’s retrieval system was originally designed for use cases with a well-established ontology, like Hetionet knowledge graph for bioscience research. That ontology applies uniformly to all research sessions. For general-purpose AI assistants, users discuss different topics across different conversations; there’s no single graph that fits all.
But what if we could build a personal knowledge graph per user? One where entities from conversations are linked, weighted by relevance, and retrieved via graph traversal seeded from the current query. A personal graph that evolves over time and grows denser as new entities and relationships are extracted from conversations and the documents users attach to them.
Another area where ENGRAM Personal Memory could work well is coding assistants. Memory for long-running AI agents, like coding assistants, is typically managed as a collection of Markdown files organized into a folder hierarchy. If the goal is “just recall a document” where each document is independent, folder hierarchy works fine. But in ENGRAM, memory context documents are stored as properties of Memory nodes that are connected to extracted entities by weighted RELATES_TO edges which enables PPR-based associative recall that surfaces relevant context even when there is no edges directly connecting conceptual nodes.
How ENGRAM Memory Works
ENGRAM creates a personal knowledge graph for each user. Every conversation and attached document is processed into entities such as people, technologies, concepts, products, locations that become nodes in the graph. When you ask a question, the system extracts entities from your query and uses Personalized PageRank, a graph traversal algorithm, to find the most relevant memories by following entity connections across your entire history.
The system has four stages.
Stage 1: Working memory
After each conversation exchange, the entities mentioned in your messages are stored in Redis as short-lived working memories. These are transient i.e., they will expire if not accessed. Think of them as the “currently thinking about” buffer.
For example, when you ask “What database should I use for the financial tracking API?”, the system extracts entities like “database”, “financial tracking”, and “API” and stores them alongside the conversation context. Each entity links to your personal knowledge graph, creating a trail of what you’ve been discussing.
Stage 2: Memory consolidation
Every few minutes, the system evaluates working memories based on four factors: how often they’ve been accessed, how recent they are, how many entity connections they have, and their base importance. Memories that score above a threshold are promoted to long-term storage.
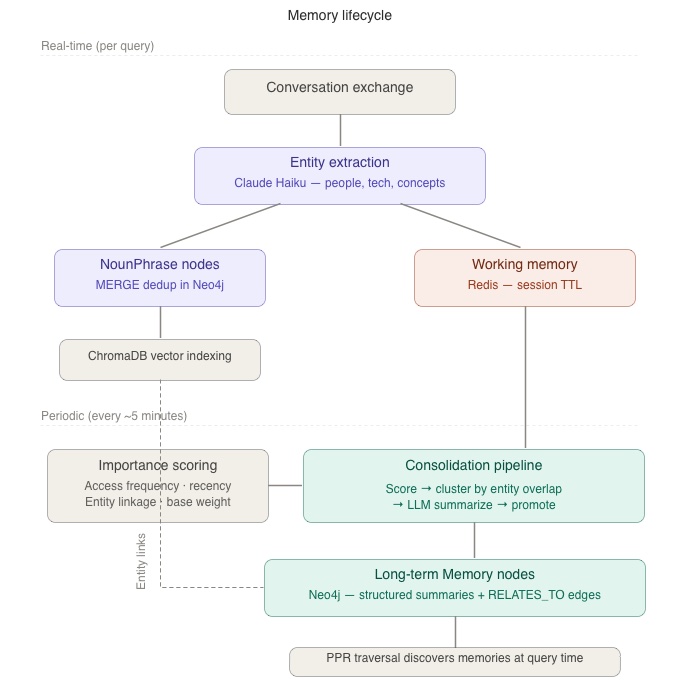
But the system doesn’t just save them as-is. Related working memories are clustered by entity overlap e.g., if you discussed PostgreSQL in one conversation and Redis caching in another, and both connect to your API project, they’re grouped together. The cluster is then summarized by an LLM into a structured format with categorized sections such as Decisions, Facts, Open Questions, and Context that preserve specific details flat summaries lose.
This structured summary becomes a permanent Memory node in Neo4j, linked to every entity in the cluster via weighted edges. The categories help the answering LLM locate relevant facts quickly when that memory is retrieved later.
Stage 3: Document integration
When you attach a document to a conversation (e.g., a technical spec, a project plan, a reference guide) the system parses it into passages (~500 tokens each), extracts entities from every passage, and links them into the same knowledge graph.
A single 2,000-word document typically contributes 50–170 entity mentions. That’s 4–8x more entity-dense than a typical 40-turn conversation. These dense entity networks are where graph-based retrieval really shines by allowing the system to find the specific passage from page 3 of your architecture doc that answers your question about authentication, even months after you uploaded it.
Stage 4: Recall via Personalized PageRank
When you ask a question, the retrieval pipeline runs in four steps:
- Extract entities from your query (Claude Haiku)
- Resolve entities against your personal knowledge graph (VoyageAI embeddings + ColBERT reranking)
- Run two-phase PPR: seed from query entities (70% weight) + memory-biased entities from your history (30% weight)
- Retrieve context: select top-scoring Memory node summaries + relevant document passages, format for LLM prompt injection
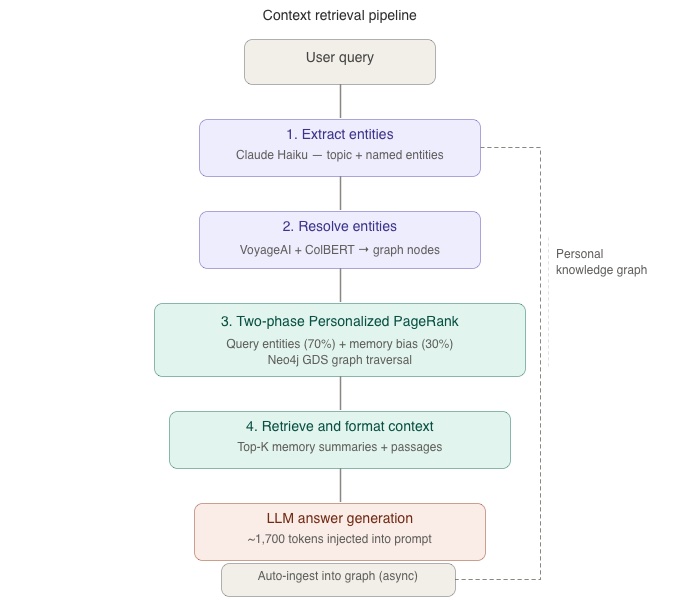
The key insight is that PPR doesn’t search text, instead it traverses connections. When you ask about “deployment”, the algorithm starts at the “deployment” node and spreads activation through every connected memory, conversation, and document passage. A memory about choosing Docker (connected to “deployment” via RELATES_TO) activates alongside a passage from your deployment runbook (connected via MENTIONED_IN). The system finds what’s relevant by following the graph, not by keyword matching or compression.
The result: ~1,500–2,000 tokens of precisely selected context injected into the LLM prompt, drawn from across your entire conversation history. No recency bias. No lossy compression.
How We Tested It
To validate ENGRAM Personal Memory method, we built an evaluation harness that compares ENGRAM against four alternative approaches on the same set of queries:
| Method | How it works | Typical tokens |
|---|---|---|
| Last-5 | Last 5 messages from most recent conversation | ~1,000 |
| Blind Summary | LLM compresses all history without seeing the question | ~1,200 |
| Query-Aware Summary | LLM compresses all history knowing the upcoming question | ~1,100 |
| Full History | All conversations concatenated (impractical for production) | ~50,000 |
| ENGRAM PPR | Graph-based retrieval via Personalized PageRank | ~1,700 |
The Blind Summary represents what production AI assistants typically do today i.e., first, compress conversation history into a rolling summary and then answer from that. The Query-Aware Summary is an idealized baseline: what if you could re-compress everything with perfect knowledge of the next question? It’s not realistic, but it establishes an upper bound for compression-based approaches.
For each query, all five methods generate an answer using the same LLM (Claude Sonnet). A separate LLM judge (Claude Sonnet) rates each answer on relevance (1–5) and completeness (1–5) without knowing which method produced it.
We tested across three scenarios of increasing complexity:
- Short conversations: 150 conversations, 10–20 turns each, 3 simulated users
- Long conversations: 25 conversations, 40–60 turns each
- Long conversations + documents: same 25 conversations with 7 attached documents (technical specs, financial guides, deployment runbooks)
Queries spanned three difficulty levels: easy (answer in a single recent conversation), medium (requires 2–3 conversations), and hard (cross-domain context from 3+ conversations).
What We Found
The Key Result
ENGRAM’ memory retrieval (PPR on a personal knowledge graph) outperforms both recency-based truncation and LLM-compressed summaries when conversation history is sufficiently long. On short conversations, LLM compression is strong, but as conversation history grows, compression gets worse and ENGRAM’s PPR selective retrieval wins decisively.
This confirms the core thesis: graph-based associative retrieval selects better context than flat compression for long, multi-session conversation histories which is the scenario personal AI assistants face in real-world.
Methodology
- Same Claude Sonnet model was used for all answer generation
- LLM-as-judge (Claude Sonnet) rates each response on relevance (1-5) and completeness (1-5)
- Pairwise win rates derived from per-condition scores
- Labels randomized (V/W/X/Y/Z) to prevent position bias
Short Conversations (10-20 turns)
| Condition | Relevance | Completeness | Avg Tokens |
|---|---|---|---|
| Last-5 (baseline) | 1.6 | 1.6 | ~900 |
| ENGRAM PPR | 2.6 | 2.4 | ~1,300 |
| Full History | 3.33 | 3.33 | ~50,000 |
| Blind Summary | 3.8 | 3.47 | ~1,700 |
| Query-Aware Summary | 4.13 | 3.8 | ~1,500 |
Long Conversations (40-60 turns)
| Condition | Relevance | Completeness | Avg Tokens |
|---|---|---|---|
| Last-5 (baseline) | 1.47 | 1.53 | ~1,100 |
| Blind Summary | 1.73 | 1.73 | ~1,200 |
| ENGRAM PPR | 2.47 | 2.53 | ~1,300 |
| Query-Aware Summary | 3.13 | 3.13 | ~1,000 |
| Full History | 4.33 | 3.93 | ~50,000 |
Long Conversations with Attached Documents – Flat Summaries
| Condition | Relevance | Completeness | Avg Tokens |
|---|---|---|---|
| Last-5 (baseline) | 1.73 | 1.60 | ~1,100 |
| Blind Summary | 2.13 | 2.40 | ~1,100 |
| Query-Aware Summary | 2.80 | 2.60 | ~1,000 |
| ENGRAM PPR | 3.07 | 2.73 | ~1,600 |
| Full History | 4.33 | 4.07 | ~50,000 |
Long Conversations with Attached Documents – Structured Summaries
Same setup as above, but Memory nodes in ENGRAM use structured Markdown summaries with categorized sections (Decisions / Facts / Open Questions / Context) instead of flat 2-3 sentence prose.
| Condition | Relevance | Completeness | Avg Tokens |
|---|---|---|---|
| Last-5 (baseline) | 1.67 | 1.60 | ~1,100 |
| Blind Summary | 2.07 | 2.40 | ~1,200 |
| Query-Aware Summary | 2.87 | 2.60 | ~1,000 |
| ENGRAM PPR | 3.13 | 2.87 | ~1,700 |
| Full History | 4.33 | 4.07 | ~50,000 |
On short conversations, compression wins. The LLM can read 10–20 turns and compress them effectively plus, there’s not enough content for graph structure to add value. But as conversations grow longer and documents are attached, the compressor faces an impossible task: squeeze everything into ~1,200 tokens without knowing what will be asked next. It drops details. ENGRAM doesn’t compress upfront — it indexes entities at ingestion and retrieves selectively at query time.
ENGRAM PPR’s Advantage Scales with Query Difficulty
The harder the question, the more PPR helps:
| Query difficulty | PPR win rate vs Last-5 |
|---|---|
| Easy (answer in recent conversation) | 53% |
| Medium (requires 2–3 conversations) | 61% |
| Hard (cross-domain, 3+ conversations) | 87% |
Easy questions (“What framework did I pick?”) can be answered from recent context. Hard questions (“Based on my investment strategy and the API I’m building, should I invest more time or money?”) require connecting information across multiple conversations which is exactly what graph traversal does.
Documents are ENGRAM PPR’s Secret Weapon
Adding 7 documents to the graph increased ENGRAM PPR’s relevance score by 27% (from 2.47 to 3.13 with structured summaries). Each document contributed ~80 entity mentions on average, creating dense networks of connections that PPR traverses efficiently.
The compression baseline degraded further with documents as it must now summarize both conversations and documents into ~1,200 tokens. ENGRAM retrieves specific passages from page 3 of a 15-page spec while the compressor has already forgotten that the spec exists.
Structured Memory Summaries Matter
When memories are consolidated, we tested two summary formats for LLM-generated summaries.
Flat (2–3 sentences): “The user is building a financial tracking API with PostgreSQL and Redis for caching.”
Structured (categorized Markdown): Decisions: chose PostgreSQL (JSON support), Redis for caching. Facts: financial tracking API, 100ms response target. Open Questions: container architecture undecided.
The structured format improved ENGRAM PPR’s win rate against Blind Summary from 67% to 73% and against Query-Aware Summary from 40% to 47%. The categories help the answering LLM locate specific facts e.g., a question about database choices goes straight to the Decisions section rather than scanning through prose.
Compression at ~30:1
ENGRAM achieves useful context selection at roughly 30:1 compression versus full history: it injects ~1,700 tokens compared to the full history’s ~50,000 tokens. Full History scores highest overall (4.33 relevance on long conversations with documents) but it is certainly impractical for production. ENGRAM approaches that quality at a fraction of the token cost.
What We Learned
Graph density is everything. PPR’s quality depends on having enough entity connections to traverse. With 5 conversations, the graph is too sparse for meaningful retrieval. With 25 conversations plus documents, PPR decisively outperforms compression. ENGRAM is a long-term investment as relevance of its recall gets better the more you use it.
Compression has a ceiling. Blind Summary scored 3.8 on short conversations but dropped to 1.73 on long ones which is a 55% degradation. It’s fundamentally limited by having to make lossy compression decisions without knowing what will be asked next. ENGRAM defers that decision to query time.
Entity extraction for queries is different than for messages. Conversation messages contain named entities (“I chose PostgreSQL”). Queries contain topic keywords (“What database should I use?”). Expanding entity extraction to include topic keywords (e.g., treating “database” as a technology entity) was essential for the pipeline to work on real queries. This is a key difference from the biomedical research domain, where queries always contain specific entity names.
Summary quality directly impacts recall quality. Memory nodes with UUID metadata scored 2.5 in relevance. LLM-generated flat summaries: 3.07. Structured categorized summaries: 3.13. The content in Memory nodes is what the answering LLM reads. In short, investing in summary quality pays off directly.
No seed knowledge graph needed. Unlike ENGRAM Biomedical Research Assistant, which relied on Hetionet (47K nodes) as a seed knowledge graph, Personal Memory bootstraps graph entirely from conversation history. The personal graph starts empty and grows organically. This makes it domain-agnostic but means the cold-start period (~20 conversations) requires patience.
Growing a Personal Ontology
Unlike biomedical research ENGRAM, which starts with Hetionet (a curated knowledge graph of 47,000 nodes covering genes, diseases, and compounds) Personal Memory starts from zero. The personal knowledge graph bootstraps entirely from conversation history. This makes it domain-agnostic, but it also means the graph needs active management to stay useful.
Our POC produced ~2,900 NounPhrase nodes from 150 conversations which is roughly 19 entities per conversation. At that rate, a user with 1,000 conversations would accumulate ~19,000 NounPhrases, many of them generic terms (“discussion”, “project”, “issue”) that pass entity extraction but fail to resolve meaningfully during PPR retrieval. Left unchecked, the graph grows noisy and retrieval quality degrades.
We’re addressing this at three levels:
- Extraction-time filtering. Better extraction prompts that distinguish between meaningful entities (“PostgreSQL”, “deployment pipeline”) and generic terms (“the project”, “that thing”). The POC showed that expanding extraction to include topic keywords was essential, but the pendulum can swing too far toward over-extraction. A confidence threshold (≥0.6) on entity resolution prevents low-quality matches from entering the PPR pipeline.
- Consolidation-time curation. NounPhrases that are mentioned once, never consolidated into a Memory node, and have no RELATES_TO edges are candidates for pruning. The consolidation pipeline can surface these low-value entities periodically (a pattern we call “morning questions”) where the user reviews 3–5 suggested entity dismissals or alias merges per day. Dismissed entities are excluded from future entity resolution, keeping the active ontology focused.
- Organic growth through use. The ontology grows denser in the domains the user actually discusses. A developer’s graph becomes rich in technology and architecture entities; a financial analyst’s graph accumulates investment and market terms. Consolidation promotes frequently-referenced entities by increasing their RELATES_TO weights. The result is a graph that naturally reflects the user’s interests and expertise — a personal ontology that no pre-built knowledge graph could provide.
The cold-start period remains real. Based on our testing, PPR needs roughly 20+ conversations to produce enough Memory nodes for useful retrieval. Seeding the graph from a user profile (e.g., topics of interest, professional domain) could accelerate this, but we haven’t tested that yet.
Where ENGRAM Personal Memory Fits in the Landscape
ENGRAM Personal Memory isn’t the only system rethinking how AI agents should handle long-term memory. Two recent research systems (A-Mem (Xu et al., NeurIPS 2025) and xMemory (Hu et al., ICML 2026)) tackle the same problem from different angles. All three reject flat memory storage and recency-based retrieval; they arrive at structure through different architectural choices.
A-Mem takes a Zettelkasten-inspired approach: each memory is an LLM-enriched note with keywords, tags, and contextual descriptions, linked to related notes through semantic analysis. When new memories arrive, the system can evolve existing notes by updating their descriptions and tags to incorporate new context. Retrieval uses embedding similarity plus linked-note expansion. The result is a flexible, schema-free system with low infrastructure requirements (vector store + LLM API).
xMemory builds a four-level hierarchy using raw messages, episode summaries, distilled semantic facts, and thematic groups as levels optimized by a sparsity-semantics objective that keeps the structure balanced. Retrieval uses a two-stage process: first selecting diverse representatives via sub-modular optimization on a kNN graph, then adaptively expanding to raw evidence only when the answering LLM’s uncertainty warrants it.
ENGRAM Memory takes a graph-first approach: entity extraction builds a typed knowledge graph where NounPhrase nodes connect conversations, documents, and Memory nodes through weighted, typed edges (RELATES_TO, MENTIONED_IN, SAME_AS). Retrieval uses Personalized PageRank that allows spreading activation from query entities through the graph structure rather than relying on embedding similarity alone.
The key differentiators across the three systems:
- Memory lifecycle. ENGRAM is the only system with a temporal consolidation pipeline — working memories in Redis are importance-scored and periodically promoted to long-term Memory nodes in Neo4j, mimicking the hippocampus sleep cycle. A-Mem and xMemory treat all memories with equal persistence; neither has a working-to-long-term promotion mechanism.
- Memory evolution. A-Mem’s ability to retroactively update existing memories as new related context arrives is a feature ENGRAM currently lacks. Our Memory nodes are immutable after consolidation. This is something we plan to explore. When new working memories cluster with entities overlapping an existing Memory node, the node’s structured summary could be updated rather than creating a separate memory.
- Retrieval personalization. ENGRAM’s two-phase PPR blends query relevance (70%) with accumulated memory weights (30%), meaning past sessions actively shape retrieval for new queries. Neither A-Mem nor xMemory personalizes retrieval based on usage history. Both are purely query-driven.
- Token efficiency. All three systems dramatically reduce context size compared to full-history injection. A-Mem achieves ~1,200–2,500 tokens per query, ENGRAM ~1,500–2,000, and xMemory ~4,700–6,600.
We plan to run ENGRAM against the LoCoMo benchmark which is the same evaluation dataset used by both A-Mem and xMemory, to achieve direct comparison on standardized metrics. Those results will tell us where PPR-based graph retrieval excels relative to embedding similarity (A-Mem) and hierarchical decomposition (xMemory), particularly on multi-hop and temporal reasoning where graph traversal should have a structural advantage.
What’s Next
LoCoMo benchmark — we’re validating against a published multi-session dialogue benchmark (Maharana et al., 2024) to compare ENGRAM with A-Mem and xMemory on standardized metrics.
Production hardening — confidence thresholds on entity resolution, personal ontology curation (surfacing low-value entities for user dismissal), and latency optimization. The graph traversal itself runs in ~200ms, but API-based entity extraction and resolution currently add ~2-3 seconds. Local models would bring total latency under 500ms.
Coding assistants — I am also interested in real-world testing of ENGRAM Personal Memory as a memory system powering coding agents like Claude Code or OpenAI Codex, where the current flat-file approach to memory could benefit from associative, graph-based recall.
References
- ENGRAM Part 1: GraphRAG with Hippocampal-Like Associative Retrieval
- ENGRAM Part 2: Unified Graph Retrieval from Long Documents and Multi-Agent Response Synthesis
- ENGRAM Part 3: Hippocampal-Inspired Memory — Working Memory, Long-Term Memory, and Periodic Consolidation
- Data and Code for the ACL 2024 Paper “Evaluating Very Long-Term Conversational Memory of LLM Agents”
- A-Mem: Agentic Memory for LLM Agents
- Beyond RAG for Agent Memory: Retrieval by Decoupling and Aggregation
- ENGRAM Personal Structured Memory codebase is available at GitHub Repository
