

The last release was quiet plumbing — every memory learned to say where it came from and what body of work it belonged to. This one is what the plumbing was for. ENGRAM can now be told what to remember rather than only deciding on its own; it can hand a slice of what it knows to a named collaborator (a person or an agent) without leaking anything else; and the memories you actually lean on grow easier to recall the more you use them. All of it private by default, and none of it shared with anyone you didn’t name.
I ended the last post by saying it was the quiet release between two loud ones — that it laid down provenance and projects precisely so that the interesting work could stand on them. This is the first of the loud ones.
It builds on a single shift in how ENGRAM remembers. For most of its life, memory reached ENGRAM two ways. Most of it was a byproduct of observation — the system watched me work in a chat or a coding session and decided, on my behalf, what was worth keeping. Some of it was already deliberate: when I saved an article or attached a document, ENGRAM mined that content into durable memory because I had chosen to create the artifact. Both are real, both stay exactly as they were. But between them they left a gap — there was no way for me, or an agent working on my behalf, to say “this, specifically, is worth remembering,” commit one fact in the middle of the work without stopping to write a whole document, and recall it on purpose later.
This release closes that gap. And once memory can be deliberately kept at the grain of a single fact, two things that were impossible before become natural: it can be deliberately shared, and it can be deliberately strengthened. Three movements: deciding, sharing, and strengthening – each one building on the last.
Deciding what to remember
The old model is capture everything, forget most. Every question I ask becomes a scrap of working memory; a noise filter throws nearly all of it away, and what survives gets consolidated into something durable. It works because the filter is ruthless. The cost is that it has no notion of intent — it cannot tell the one sentence I would have underlined from the forty around it.
The new model is the opposite: capture little, keep most. When I decide something is worth remembering, the decision itself is the signal. There is no filter to survive, because applying judgment up front is the whole point.
There is one subtlety here that I cared about getting right, because the next project depends on it. You never write a memory directly. Even when I deliberately commit one, I don’t hand ENGRAM a finished memory node. Instead, I hand it a note and an intent, and ENGRAM derives the memory: it pulls out the entities, links them into the graph, scores it, and stamps it with where it came from. What I own is the judgment — that this matters. What ENGRAM owns is the representation.
That sounds like a technicality, but it buys something specific. Because every memory has a real derivation behind it (not just a blob of text I typed) the system can later re-examine why it believes something, which is exactly what belief revision will need. And it means there is one pipeline for everything: observed memory, saved articles, recorded conversations, and now deliberate notes all flow through the same machinery. The price is honest to state: there is no verbatim guarantee. The meaning is preserved; the exact wording is ENGRAM’s to restructure. So for the things where the literal characters matter such as an exact command, a config value, or an IP address, the right move is to save an article, not to “remember” a sentence. Memory is for meaning; artifacts are for fidelity.
Deliberate memory arrives four ways now. One has been part of ENGRAM from the start; the other three are what this release adds, and they rise in ceremony from a one-word gesture to a reviewed handshake:
- Create an artifact – the original way, the one that predates this release. Save an article or attach a document, and ENGRAM extracts its content into durable, high-importance memory on the spot. The deliberate act is producing the artifact; the keeping follows on its own. It works at the grain of a whole document — the same channel behind the “save an article when the exact words matter” point above. The three below reach finer, down to one fact, without making you write a document first.
- Just remember it. The lightest gesture – “remember this.” It commits on the spot, skips the noise filter, and is recallable immediately. In chat, I can also pin an assistant’s response and have it digested into memory, something the system used to exclude by default.
- Reflect at the end. When a session or a task wraps up, the work that accumulated along the way can be gathered into a short recap (a structured “here’s what this session was about”) which ENGRAM then breaks apart into individual memories, one per topic. This is the closest thing ENGRAM has to sleeping on it: the salient set is distilled at the boundary, not mid-stream.
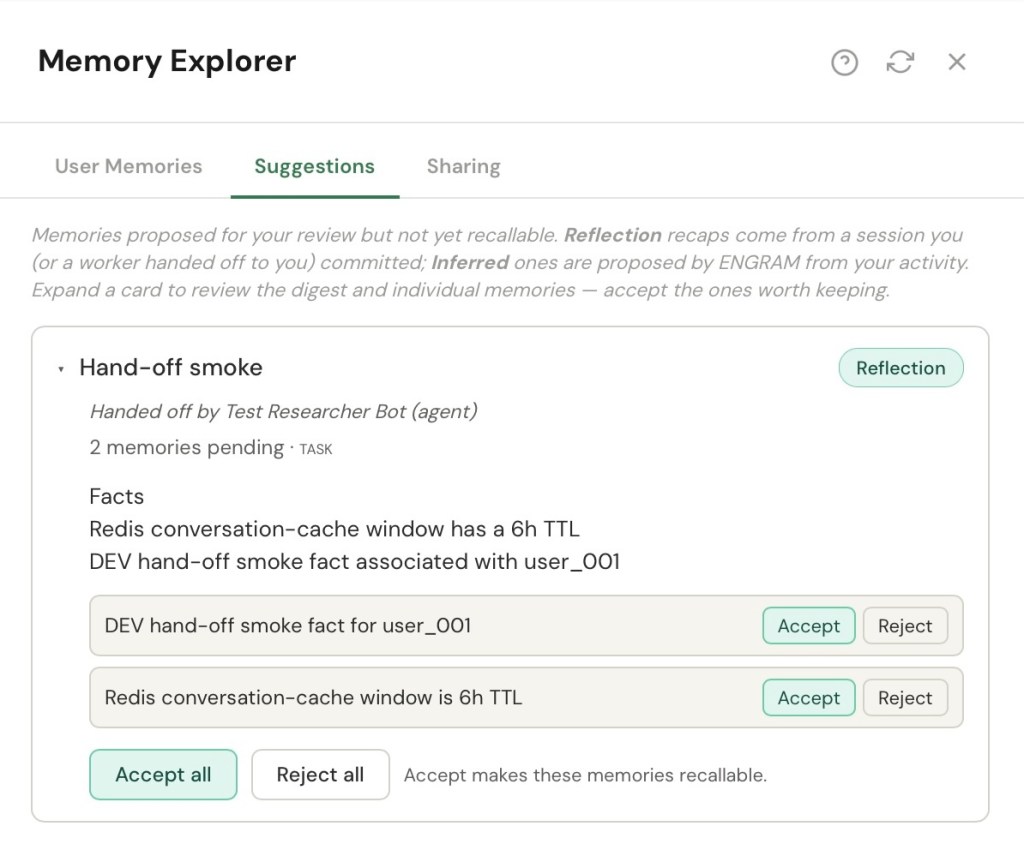
- Suggest, then accept. This is the quiet keystone. An agent — or ENGRAM’s own reflection step — can suggest memories, but a suggested memory is invisible to recall until I accept it. Nothing an agent proposes enters my memory on its own say-so. There is always a yes in between. The suggestions wait in an inbox; I accept or reject a whole recap at a glance.
That last rule (suggest, then accept) is what makes everything after it safe. It is the seam where another mind’s idea of what I should remember becomes my memory, and only with my consent.
Sharing what you know
Here is the headline, and the place where the last release pays off directly.
A clarification first, because it’s the whole point. Inside my own substrate, memory has always moved freely – reaching across conversations, sessions, and projects is exactly what recall is, and it always has been. What’s new is letting a memory cross to a different user at all. Until now it never could; that boundary was absolute. This release opens it – deliberately, narrowly, and on my terms.
Memory in ENGRAM is private by default, which is not a casual default. Earlier this year I traced and shut a cross-tenant leak (a path by which one user’s memory could bleed into another’s recall). The lesson I took from it was that the only safe foundation for sharing is one that shares nothing unless explicitly told to. So sharing here is built fail-closed: deny everything, then grant exactly what you name. There is no “public” memory, no global pool, no “share with everyone.” That door doesn’t exist.
When I do share, two rules hold.
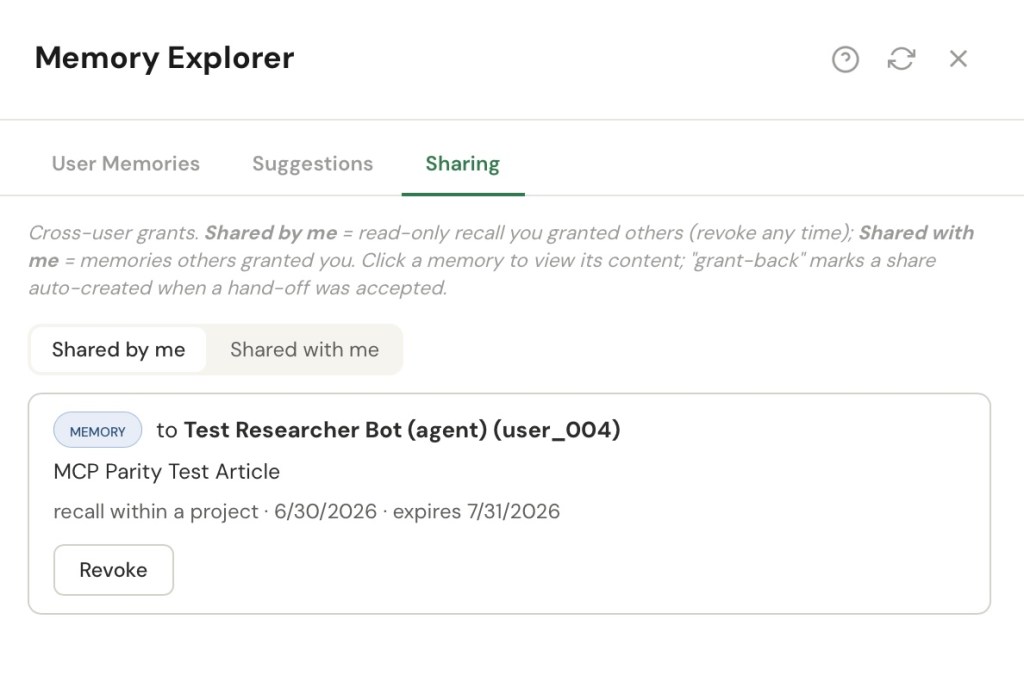
I share to named collaborators. Always a specific person or a specific agent — never an audience. A memory is “shared” only when at least one grant points it at someone.
I share at the narrowest grain that serves the work. Three grains, and I pick the smallest that does the job:
a single memory — one specific thing I want a collaborator to have
a context — one conversation, or one coding session
a project — an entire body of work, every surface that fed it
That third grain (a whole project) exists only because of the last release. Projects were the thing the previous post quietly built; sharing is the thing they were built for. “Give this collaborator everything from the migration work” is a single gesture now, and because a project is a living namespace, the collaborator automatically sees new memories created there later — not a frozen snapshot.
The collaborator can be a person or an agent, because underneath this release ENGRAM finally has a single model of a “user” that is human or agent alike — the same memory, the same pipeline, the same sharing machinery serving both.
The two keys
The part I’m most pleased with is how sharing refuses to over-share. A borrowed memory reaches a collaborator only when two keys both turn.
The first key is mine: a memory only travels if I’d actually exposed it at the level I’m sharing. My own task-private scratch (notes I kept to a single task inside a project) doesn’t fly out just because I shared the project; only what I’d placed at the project level goes. Sharing a coarse grain never reaches down and scoops up the finer, more private memories beneath it. The second key is the grant itself: someone has to have been named.
Both, or nothing. A broad grant can’t accidentally sweep up my own narrowly-scoped scribbles, while a deliberate share of one specific memory still works exactly as intended — because naming a single memory is me turning the first key by hand.
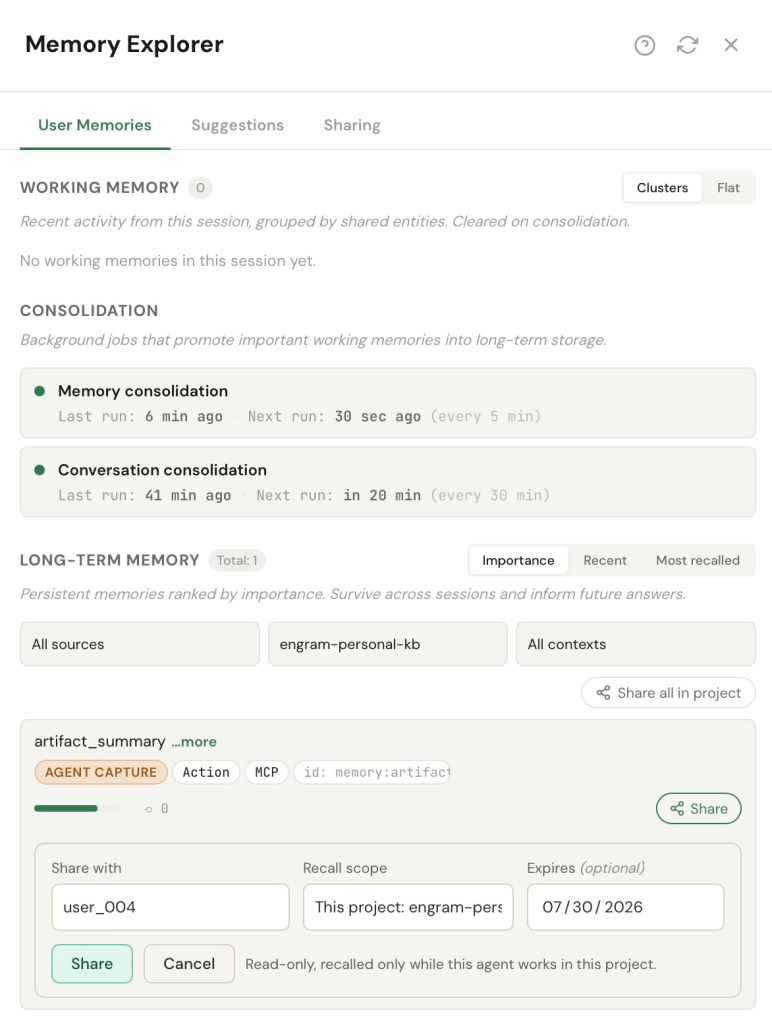
There’s a second question beyond who gets a memory: where the recipient can use it. When the recipient is an agent, a share can be scoped — pinned to a project, or to a single conversation — so the agent recalls it only while working there, never bleeding into its other work. Project scope is the one that earns its keep: one agent can run across several projects and stay walled off in each. (A person recalls in their own workspace, so a share to a human is simply theirs to use wherever they work.) The two keys decide whether a memory reaches someone; scope decides where it surfaces once it has.
Sharing, concretely. The case where this bites hardest is delegation. I hand an agent a research task; it splits the work into pieces and spins up a sub-agent for each, sharing to every sub-agent only the memories that piece needs, scoped to that sub-task. Each sub-agent recalls exactly the slice it should and nothing wider — and when its piece is done, the scope closes behind it. That’s least privilege applied to memory: the blast radius of any one share is precisely the job it was made for.
Two speeds of sharing
Not all sharing wants to be permanent, so there are two kinds.
Durable sharing is for expertise — knowledge I want a collaborator to keep drawing on. It’s a standing grant: made once, good until I revoke it, fully audited so I can always see what I’ve shared and with whom.
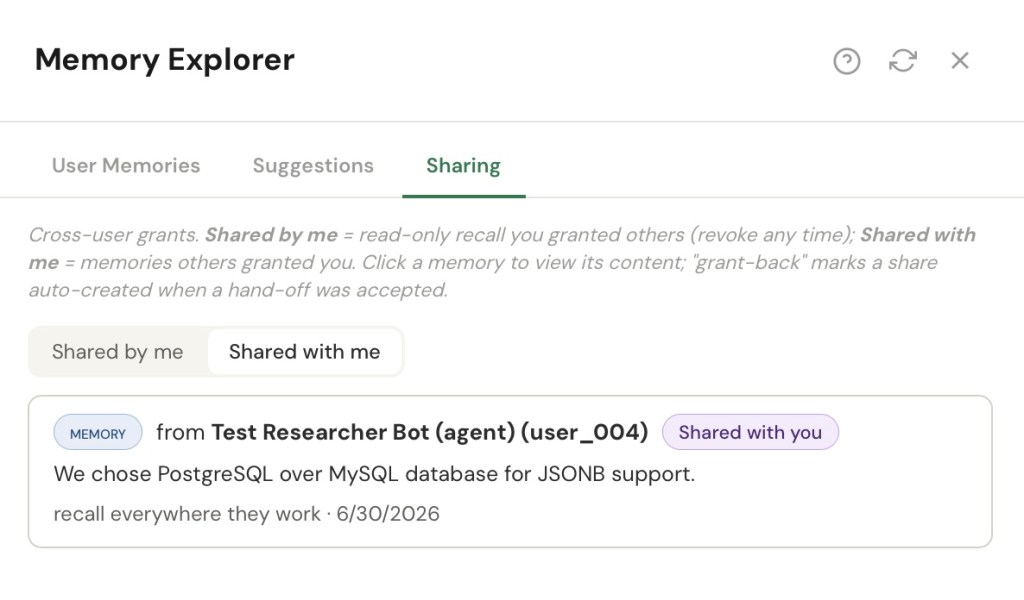
Ephemeral sharing is for the hot path of delegation. When a coordinating agent fans a task out to a specialist, it can hand that specialist exactly the live working notes the task needs — and nothing else. This share is a snapshot, not a live feed, so my later edits never leak; it’s read-only; and it self-cleans, expiring on its own once the task is done. It’s the lightweight, disappearing version of sharing, built for “here, you’ll need these three things for the next ten minutes.”
Who owns what a worker produces
When an agent does a piece of work for me and hands back the result, a small question has to be answered: who owns the durable memory the work produced? The answer crystallizes at hand-off. If the agent was acting under my own authority, what it learned is simply mine. If it’s a distinct agent with its own identity, it suggests the durable memories back to me, I accept them — and the agent keeps a grant so it can still recall the work it did. Either way, the durable owner is whoever set the task; the worker keeps a way back to its own output. And sharing only ever passes recall, never authorship: a memory you shared with me is one I can read, not one I can rewrite.
Strengthening what gets used
The third movement is the smallest in code and, I think, the most human.
Until now, recalling a memory left it unchanged. A memory I reached for every day and a memory I’d touched once sat at exactly the same standing forever. Real memory doesn’t work that way — the things you use get easier to reach, and the things you never revisit fade into the back. This release gives ENGRAM the first half of that: spaced repetition.
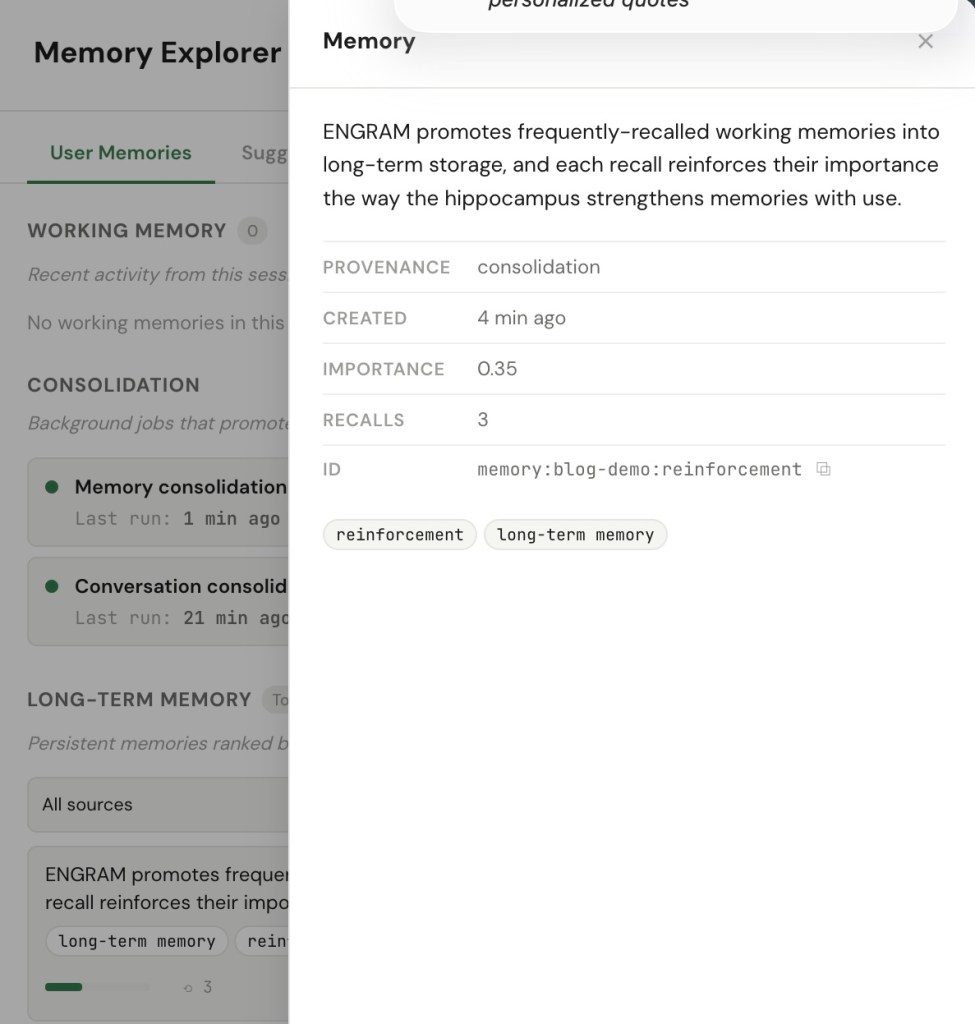
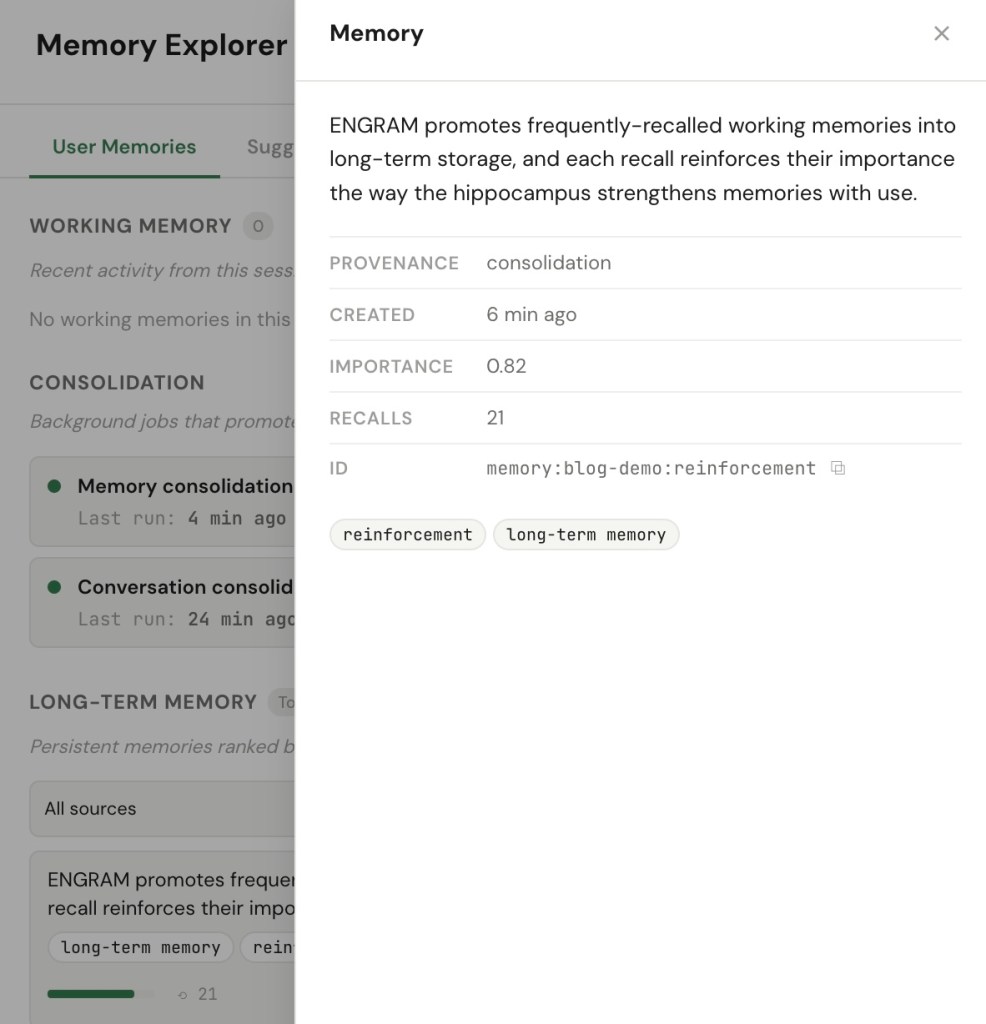
When a memory actually earns its place in the context that answers one of my questions — not merely matches a keyword, but is genuinely among the handful the system leaned on to reply — it gets a small nudge upward in importance. And because ENGRAM ranks what to recall partly by importance, that nudge makes the memory a little easier to surface next time. Use it and it rises; ignore it and it stays put. Over weeks, my most-used knowledge drifts naturally to the top of recall without my ever curating it.
The nudges are deliberately gentle. Each one is smaller than the last, so a memory approaches a ceiling but never rockets to it; there’s a cool-down so a flurry of activity can’t inflate anything; and nothing is ever born at the top — height is earned by reuse, one nudge at a time.
Reinforcement, concretely. A fact I lean on keeps proving useful: each time it actually informs an answer in chat, it earns a small nudge upward, so it surfaces a little faster next time. A fact I never return to simply stays put, and a cooldown keeps a busy afternoon from inflating anything. One subtlety ties this back to sharing in a way I like: only the owner’s use strengthens a memory. If I’ve shared a fact with you and you recall it a hundred times, that usage is yours — it never moves my ranking. Reinforcement reflects how I use my own mind, not how popular a memory is with everyone I’ve lent it to.
I’ll be honest about the half that isn’t here yet: memory can strengthen, but it can’t yet fade. There’s no forgetting arm — nothing decays, nothing gets retired. That’s not an oversight; it’s the doorway to the next hard problem, and it belongs there rather than here.
Why this was worth it
The last post gave every memory an honest answer to where did you come from and what are you part of. This one gives them three new capabilities: a memory can now be deliberately kept, deliberately shared, and quietly strengthened by use. None of it weakens the privacy floor — sharing is fail-closed, named-only, narrowest-grain, and bound to its purpose. The cross-tenant lesson from earlier this year didn’t get patched over; it got built into the foundation, so that the very first time memory could cross between users, it crossed carefully.
A note on how this shipped. None of it switched on the day it merged. Each piece (the deliberate-remember paths, the sharing model, the reinforcement curve) went out behind a flag held off, so the new machinery could be proven byte-for-byte identical to the old behavior before it ever carried real memory. That’s the discipline a foundational release deserves: present but quiet, validated against what came before, and only then enabled. That step is done now — it’s live.
A note on what “agentic” actually means here. Every capability in this post is a verb something can call, not just a button a human clicks. To keep memory there are remember, reflect, and accept; to share it, grant and revoke plus the ephemeral working-memory hand-off. A few have a home in the Memory Explorer too — such as, the remember affordance, the Suggestions inbox, the share-and-revoke controls — but all of them an agent can invoke directly, over the same tool interface Claude Code and Claude Desktop already speak to ENGRAM. That’s the line between a memory feature and a memory substrate: a feature is something you use; a substrate is something other software can build on. (Reinforcement is the exception that proves the rule — there’s no verb for it, because you never invoke it; it just happens as you lean on what you’ve kept.)
What’s next
With deliberate memory in place and a careful way to share it, the next project is the natural other side of the same coin. Sharing answers how does a memory get to a collaborator. It doesn’t yet answer how does a collaborating agent deliberately reach for it. Today the in-app chat recalls automatically — entities in, relevant memory out — but an autonomous agent working across the shared substrate has no clean, callable way to say “recall what I know about X” and act on the answer. That recall surface is the next build: Multi-Agent Memory Recall & Sharing, whose first phase landed today. It’s what turns everything in this post from a substrate that can be shared into one that collaborating agents can actually think with. That’s the next post.
And still circling, in design: Memory Fact Update — the belief-revision problem I keep returning to, the confidently-wrong memory that has quietly gone stale. It’s also where forgetting lives — the fade I admitted was missing above. Teaching ENGRAM to notice a contradiction, retire the old claim, surface the new one, and never throw away the record of what it used to think is the harder of the two projects, and it’s deliberately sequenced second. It begins in earnest now that the foundation underneath it — deliberate memory, and a safe way to share it — is built.
Two posts ago the mind learned to remember. One post ago it learned where its memories came from. Now it has learned to be told what to keep, to lend a piece of itself to someone it trusts, and to lean a little harder on the things it actually uses. The loud releases have started.
ENGRAM Knowledge Hub is in private beta. Release notes and documentation live at pvelua.net, including a running record of the work behind posts like this one.
For the background this builds on:
- When Graphs Remember Better Than Summaries – How hippocampal-inspired memory consolidation and Personalized PageRank give AI assistants structured recall across conversations and documents
- ENGRAM Knowledge Hub: A Personal Knowledge Graph That Grows With Your Research – Most LLM tools forget what you taught them last week. ENGRAM turns your conversations, documents, and research into a personal knowledge graph with recall by relevance, not recency
- Claude Code and ENGRAM Knowledge Hub: recalling the good memories together – Long-term memory across research, planning, and the iterative work of building
- Completing the Mind: ENGRAM Now Remembers Conversations from Claude Desktop, ChatGPT, and Gemini – The last missing ingestion path — the research I do with assistants outside ENGRAM
- A Mind That Knows What It’s Missing: ENGRAM Now Finds and Closes Its Own Gaps – Knowledge Health: gap analysis, approval-gated closures, and a standing read on the knowledge base’s own condition
- Where Memories Come From: ENGRAM Learns to Track Provenance and Group by Project – ENGRAM could already remember an enormous amount. What it could not always say was where a given memory came from, or which body of work it belonged to.

2 Comments