

ENGRAM could already remember an enormous amount — articles, code sessions, conversations from half a dozen assistants. What it could not always say was where a given memory came from, or which body of work it belonged to. This release fixes that. Every memory now carries a clean, three-tier line back to its source, and every source now hangs off a project. It is quieter than the last few releases, and more foundational than any of them.
I ended the last post by pointing at the blind spot that worries me most: a memory that is confidently wrong — something I wrote down carefully that has quietly gone stale. Teaching ENGRAM to notice that, retire the old claim, and surface the new one is belief revision, and it is genuinely hard. The system has to detect the contradiction, decide which claim wins, and keep the history honest.
This post is not that post. It is the one that has to come first.
Because here is the thing I ran into the moment I started designing belief revision: before a mind can change what it believes, or share what it knows with another mind, every individual memory has to be able to answer two very basic questions. Where did you come from? And what are you part of? For most of ENGRAM’s life it could only half-answer the first and not answer the second at all. This release closes both gaps. It is plumbing — but it is the plumbing the next two projects stand on.
The shape of the problem
ENGRAM’s memory is derived. I never write a memory directly; the system distills them from things I actually do e.g., a conversation in ENGRAM Chat, a coding session in Claude Code, a research chat I had in Claude Desktop and recorded later, or an article or document I saved. Each of those is an activity surface: a place where thinking happened that was worth keeping.
The clean mental model is a chain of three tiers:
User → Context → Artifact
The user is the ultimate owner of the memory. The context is the activity surface that produced it such as the conversation, the session, the capture. The artifact is the optional thing that activity left behind e.g., an article or a document. Read it left to right and it answers the provenance question exactly: this memory belongs to me, it came out of that conversation, and here is the write-up it produced.
That is the model I wanted. The model I actually had was subtly broken in two different places.
Problem one: the impostor conversation
The first break was in how ENGRAM handled a memory that came from an agent acting directly — not from a chat, but from a tool call. When I run a /sync-to-engram-kb command in Claude Code, it pushes an article straight into the knowledge base with no conversation behind it. There are no turns, no back-and-forth, no messages. It is a file capture, not a discussion.
But the memory still needed a context tier — every memory does. So the old design did something expedient and, in hindsight, wrong: it synthesised a fake conversation to stand in as the context. A :Conversation node with zero messages, a made-up title, and a source label that quietly marked it as not-really-a-conversation.
This was a shortcut taken to avoid a schema change, and it leaked everywhere:
- It was semantically false. A direct file capture is not a conversation. Calling it one muddied the one model I most needed to stay clean.
- It polluted the External tab. The chat sidebar lists my real external conversations — the genuine ChatGPT and Claude Desktop research I have recorded. These fake captures were swept in alongside them, showing up as empty, rows with no content.
- It threw away the real story. The sync command actually knew the good provenance — the repository and the file path on disk. The fake-conversation node discarded all of it. A row that could have read “Synced from
pvelua/engram-kb · docs/architecture.mdvia Claude Code” instead rendered as a blank “ad-hoc capture.”
The fix is the obvious one once you stop trying to dodge the schema change: give that third kind of context its own node. A first-class :Context node now represents a direct agent capture while keeping the conversation and the code session exactly as they were, and adding a proper sibling for the case that is neither.
User
│ owns
▼
Context ◄── one of: a Conversation, a CodeSession, or (now) a direct Context capture
│ derived from
▼
Artifact ◄── an Article or a Document (optional — many memories produce none)
The new node carries what the impostor threw away: which agent produced it, the repository, the file path, a clean human-readable label. The artifact links to it with the same DERIVED_FROM edge that articles already used for conversations, so all the existing “show me what this came from” machinery worked on it for free. And the memory itself barely changed as it already carried an abstract pointer to “its context,” indifferent to what kind of node sat on the other end. Two small property updates, and the retrieval behaviour was identical. No re-indexing, no recompute. The provenance got honest without the memory layer noticing.
The best part is what vanished from the UI. The External tab went back to listing only real conversations. The empty rows disappeared. And the provenance moved to where it actually belongs — onto the article itself, as a quiet “Source: Claude Code · pvelua/engram-kb · docs/architecture.md“ line you can read at a glance.

:Context provenance — the claude_code · engram-personal-kb · docs/… source the old “ad-hoc capture” row used to discardThere were only four of these impostor rows in production. The whole migration was a few minutes of work. But I did not want a permanent split-brain where old captures lived as fake conversations and new ones lived as proper contexts — that doubles every read path forever, for a few rows. So they got migrated cleanly into the new model, and the fake-conversation idea was retired for good.
Problem two: memories with no home
The second break was bigger, and it is the one that actually blocks what comes next.
By this point ENGRAM had four activity surfaces. Three of them could be grouped into a project — a single body of work that ties together everything belonging to it, regardless of which tool produced it. A code session knew its project (the Git repository). An external conversation could carry one. An agent capture could carry one. But the fourth surface — an ordinary conversation in ENGRAM Chat, the most-used surface of all — could not. It floated free, attached to nothing above it.
| Surface | Could it belong to a project? |
|---|---|
| External conversation (Claude Desktop, ChatGPT, …) | yes |
| Code session (Claude Code, Codex, …) | yes |
Agent capture (the new :Context) | yes |
| In-app ENGRAM Chat conversation | no |
That asymmetry sounds like a cosmetic gap. It is not. It is the thing standing between me and the two projects I most want to build.
Here is why. The next major capability on the roadmap is the Agentic Memory project which will allow a user (person or agent) deliberately author memory mid-task and selectively share a slice of it with a collaborator. Not all of it as that way lies polluting everyone’s recall with everyone else’s noise (the exact cross-tenant bleed a fail-closed fix deliberately shut down earlier this year). The sharing has to be selective, and one natural unit to select is a project: “share everything from the migration work with this agent,” or “give my collaborator just this one research thread.” If the most common kind of conversation cannot belong to a project, it cannot be shared at the project level, and the whole model has a hole in the middle of it.
So this release closes the asymmetry. Every activity surface — including in-app chat — now hangs off a :Project. A project is identified by a simple, stable key (the user plus a name), and crucially it is a single namespace: the conversations I have in ENGRAM Chat about a piece of work, the code sessions Claude Code ran on that same repository, the research I recorded from Claude Desktop, and the articles I synced — all of them can converge on one project node when they share a name. One project, one body of work, every surface that fed it.
Project "engram-kb"
├── ENGRAM Chat conversations (in-app)
├── Code sessions (Claude Code / Codex, by repo)
├── External conversations (Claude Desktop / ChatGPT / Gemini)
└── Agent captures (direct :Context syncs)
There was a design choice I am glad I got right here. The project link lives on the conversation, and articles and memories inherit their project through it rather than each carrying their own copy. That sounds like a detail, but it is what makes the system pleasant to live with: moving a conversation to a different project is a single edge re-point. Its articles and its memories follow automatically — nothing has to be hunted down and rewritten. If I had denormalized the project onto every memory, every move would be a fan-out update and every rename a migration. Keeping it transitive keeps it cheap.
Seeing it: the Projects fly-out
A data model nobody can see is just a promise. So projects surface in the UI now, the same way across all three places that needed them — Chat, Knowledge Base, and Coding Sessions. A small Projects icon sits beside the column title; clicking it slides out a panel listing every project, with a search box and a + New button.
Each project tile shows what is in it at a glance: a composite count of conversations, articles and documents, and sessions, plus when it was last active. Selecting a project pins it across all three surfaces at once — pick a project in Chat and the Knowledge Base and Coding Sessions tabs scope to it too, and the choice survives a reload. An explicit All Projects entry is the no-filter default, for when I want to see everything.
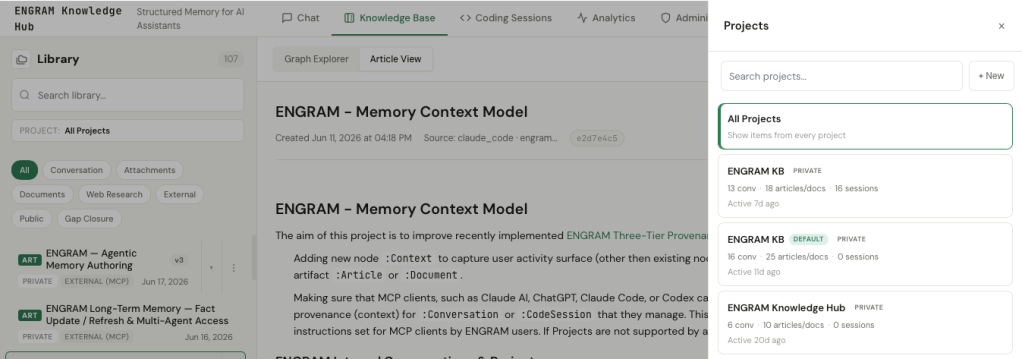
And because a conversation can land in the wrong place, things can move. A triple-dot menu on a conversation (internal or external) or an agent-captured article opens a target-project picker. The move re-points a single edge and writes a small audit record of where it went and when — and, true to the transitive design, the articles and memories underneath follow without a fuss. Two kinds of things deliberately cannot move: code sessions, which are bound to their repo, and conversation-derived articles, whose project is inherited and shown read-only as “Project: X · via that conversation.” You regroup those by moving the thing they hang off, not by detaching them.
Why this was worth a release
None of this lights up a dazzling new feature on day one. There is no agent doing clever new work, no new kind of retrieval. What there is, instead, is a memory layer that can finally answer two questions cleanly for every single thing it holds: where did you come from, and what are you part of.
That is exactly the foundation the interesting work needs. Sharing needs projects, because a project is the unit you share. Belief revision — the confidently-wrong problem I keep circling — needs provenance, because to retire a stale claim and trust a fresh one, the system has to know precisely which source each belief rests on, and be able to keep the old source on the record even after the belief moves on. You cannot honestly change your mind if you cannot say where your current opinion came from.
So this is the quiet release between two loud ones. The mind has learned to remember, to knit itself together, and to notice its own gaps. Now it has learned to keep an honest record of where each memory came from, and to file each one under the work it belongs to. That is not the headline. It is the thing the headlines will stand on.
What’s next
With provenance clean and projects in place, the work this whole release was quietly clearing the way for can begin. It comes in two parts.
The first project (already well underway) is Agentic Memory. Until now, every memory ENGRAM holds has been a byproduct: something the system observed me doing and decided, on my behalf, was worth keeping. What it has never had is a way for me — or an agent working on my behalf — to make the deliberate judgment “this, specifically, is worth remembering” and commit it mid-task, then recall it deliberately later. That is one half of Agentic Memory: the shift from remembering what was observed to remembering what was decided.
The other half is selective sharing — and here the project this post describes pays off directly. A memory is private by default. When I choose to share it, I share it to named collaborators (never to everyone — global memory is a cross-tenant bleed), and I share it at the narrowest grain that serves the collaboration: a single memory, a context, or a whole project. That last option exists only because of the projects feature in this very release. And the collaborator can be a person or an agent — because underneath, ENGRAM is moving toward a single model of a “user” that is human or agent alike, the same memory pipeline serving both, differing only in how they register.
Behind that, in design now, is the second part: Memory Fact Update — the belief-revision problem I keep circling. ENGRAM already retires an old article when a newer version supersedes it; this teaches it to do the same one level down, at the level of individual facts — to notice when fresh research contradicts something it already believes, retire the stale claim, surface the new one, and never throw away the record of what it used to think. It is the harder of the two, and deliberately sequenced second: it begins in earnest once the authoring-and-sharing foundation is built. More on it when the design firms up.
Two projects, then, standing on the plumbing this post laid down. Neither could have begun until a memory could say where it came from and what it belonged to. Now they can.
ENGRAM Knowledge Hub is in private beta. Release notes and documentation live at pvelua.net, including a running record of the work behind posts like this one.
For the background this builds on:
- When Graphs Remember Better Than Summaries – How hippocampal-inspired memory consolidation and Personalized PageRank give AI assistants structured recall across conversations and documents
- ENGRAM Knowledge Hub: A Personal Knowledge Graph That Grows With Your Research – Most LLM tools forget what you taught them last week. ENGRAM turns your conversations, documents, and research into a personal knowledge graph with recall by relevance, not recency
- Claude Code and ENGRAM Knowledge Hub: recalling the good memories together – Long-term memory across research, planning, and the iterative work of building
- Completing the Mind: ENGRAM Now Remembers Conversations from Claude Desktop, ChatGPT, and Gemini – The last missing ingestion path — the research I do with assistants outside ENGRAM
- A Mind That Knows What It’s Missing: ENGRAM Now Finds and Closes Its Own Gaps – Knowledge Health: gap analysis, approval-gated closures, and a standing read on the knowledge base’s own condition

1 Comment